
在分布式系统中,缓存与数据库的数据同步是确保数据一致性的关键措施,分布式缓存数据同步涉及到的关键环节包括缓存更新机制、数据写入冲突解决、缓存和数据库间的同步策略等,下面将深入探讨如何同步数据库和缓存数据,以确保系统的数据一致性和高性能:

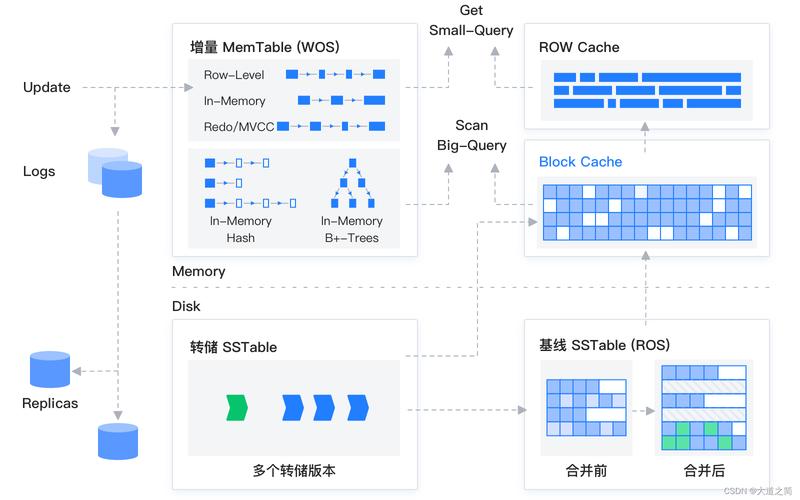
1、采用基于版本控制的缓存更新机制:引入版本号可以有效控制数据的更新顺序,确保缓存中的数据与数据库中的数据保持同步,每当数据库数据更新时,相应的版本号也随之更新,缓存中的相应数据项在访问时检查版本号,若发现版本不匹配,就从数据库中重新加载最新数据,并更新缓存中的数据及版本号。
2、设置合理的缓存过期时间:为缓存数据设置合理的过期时间,可以在数据变更不频繁的场景下减少对数据库的访问,缓存过期后,再次访问该数据时会从数据库中拉取最新数据,并在缓存中更新,从而保证数据的一致性,合理的过期时间还能避免缓存占用过多的内存资源。
3、解决数据写入冲突:在高并发的环境下,多个进程或线程可能同时尝试更新同一份数据,这就需要一种机制来避免写入冲突,通过锁机制或版本号比对的方式,可以确保同一时刻只有一个操作能够更新数据,其他并发操作需要等待或采取其他策略,如重试逻辑,直到它们可以安全地更新数据。
4、引入缓存一致性协议:通过引入缓存一致性协议,如Cache Invalidation Protocol或Distributed Invalidation,可以有效地处理分布式环境下的缓存一致性问题,这些协议定义了缓存失效、更新消息的传播机制,确保所有缓存节点的数据能够在数据库数据变更后及时更新或失效。
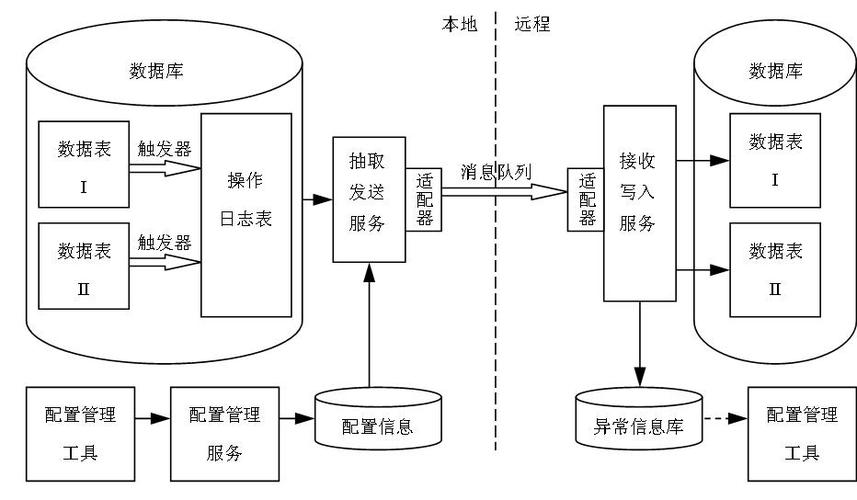
5、利用数据库日志:结合数据库的日志(如MySQL的binlog),可以通过监听日志变化来实现缓存与数据库间的同步,当数据库数据发生变化时,同步操作可以直接获取变更的数据,并更新或失效缓存中的相关数据,从而保持数据一致性。
6、选择合适的同步方案:根据不同的业务场景,选择合适的数据同步方案至关重要,在读多写少的场景下,可以采用“CacheAside结合消费数据库日志做补偿”的方案,这种方案下,缓存主要承担读操作,数据库的写操作完成后,通过异步方式更新或失效缓存中的数据。
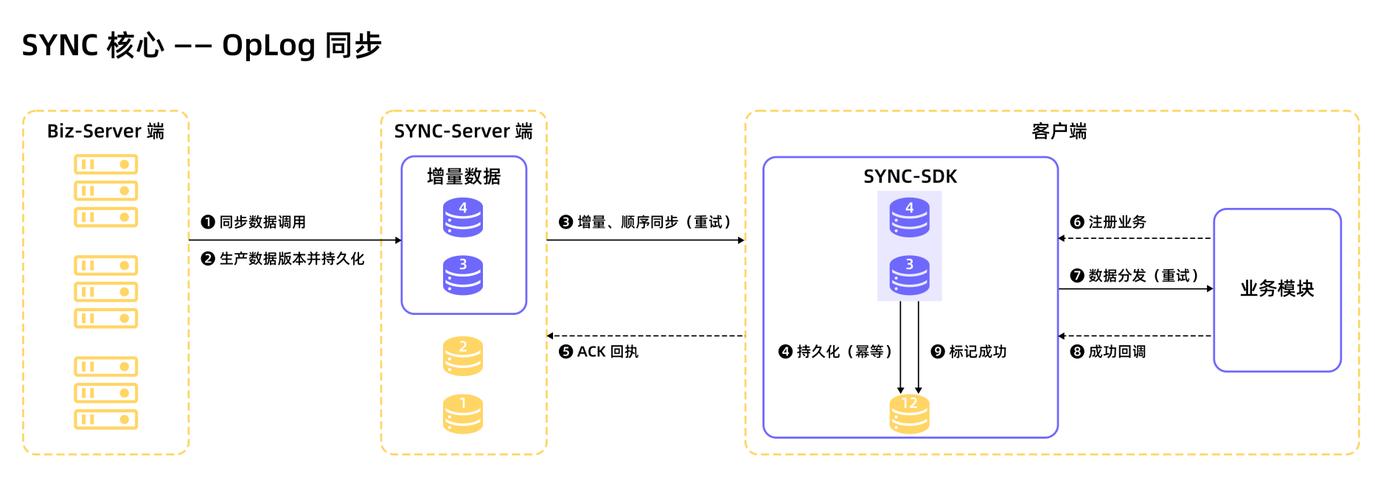
7、使用中间件来辅助同步:在复杂的分布式系统中,手动维护数据同步可能会引入错误且效率低下,使用中间件,如消息队列(RabbitMQ、Kafka等),可以解耦数据生成者和消费者,通过发布订阅模式实现缓存与数据库间的数据同步,中间件还可以保证消息的可靠传递和顺序性,进一步确保数据一致性。
在实施上述策略的过程中,还需注意以下几点:
异常处理:在设计数据同步方案时,需要考虑异常情况下的处理逻辑,如网络延迟、节点故障等,确保系统的稳定性和数据的最终一致性。
性能考量:数据同步操作不应过度影响系统的性能,尤其是在高并发场景下,同步策略应尽量减少锁竞争和网络传输开销。
监控与测试:实施数据同步方案后,需要有完善的监控和测试机制,确保数据同步的正确性和效率,及时发现并解决潜在的问题。
分布式缓存数据同步是分布式系统设计中的一个核心问题,需要综合考虑缓存更新机制、数据写入冲突解决、缓存和数据库间的同步策略等多个方面,通过精心设计和合理配置,可以实现缓存与数据库间的数据一致性,从而保障系统的稳定运行和高性能访问。
【版权声明】:本站所有内容均来自网络,若无意侵犯到您的权利,请及时与我们联系将尽快删除相关内容!

发表回复