
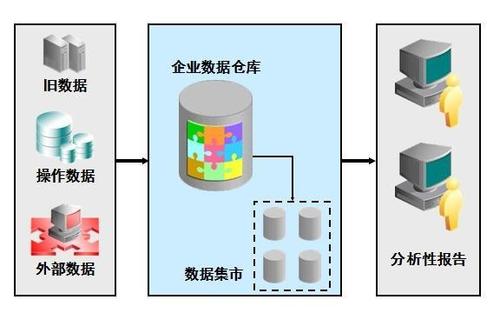
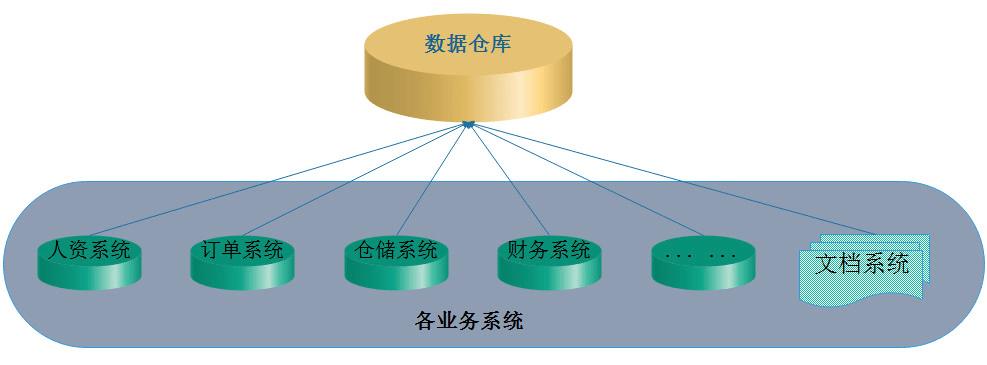
大型数据仓库是用于存储和管理大量数据的系统,通常这些数据来源于多个不同的数据源,它们被设计为支持复杂的查询操作和分析任务,以供企业决策支持、报告生成和数据挖掘等用途,以下是关于大型数据仓库的详细信息:


数据仓库架构
数据抽取、转换和加载(etl)
抽取:从各种源系统中提取数据。
转换:将数据转换成统一格式,进行清洗、合并和增强。
加载:将转换后的数据加载到数据仓库中。
数据模型
星型模式(star schema):一种多维数据模型,由一个或多个事实表和多个维度表组成。
雪花模式(snowflake schema):星型模式的变体,其中维度表进一步规范化成多个相关表。
存储
关系数据库管理系统(rdbms):传统的基于表格的存储方式。
列式数据库:优化了读取速度,特别适用于大规模数据分析。
分布式文件系统:如hdfs,用于处理极大规模的数据集。
关键特性
可扩展性
能够处理和存储日益增长的数据量。
通过增加硬件资源来提升性能和容量。
高性能
优化查询处理,减少响应时间。
使用索引、分区和物化视图提高查询效率。
高可用性
系统设计保证持续运行,最小化停机时间。
数据备份和恢复机制确保数据安全。
安全性
实施严格的访问控制和身份验证。
数据加密和审计日志保护敏感信息。
技术组件
数据库管理系统(dbms)
管理数据仓库中数据的存储和检索。
支持sql和其他查询语言。
在线分析处理(olap)
提供多维数据分析能力。
支持复杂的查询和数据聚合。
数据集成工具
自动化etl过程。
支持多种数据源和目标系统。
报表和数据可视化工具
将数据转换为图表、图形和仪表板。
帮助用户理解数据趋势和模式。
相关问题与解答
q1: 数据仓库和数据库有什么区别?
a1: 数据仓库专注于存储历史数据以供分析和报告之用,而数据库通常用于存储事务性数据,支持日常业务操作,数据仓库是面向主题的、集成的、相对稳定且反映历史变化的,数据库则通常是面向应用、当前值和实时更新的。
q2: 如何确保数据仓库的性能?
a2: 确保数据仓库性能的方法包括:使用适当的数据模型和索引优化查询;定期维护和调优数据库;使用分区和物化视图提高查询效率;以及选择适合数据仓库工作负载的硬件和存储解决方案,监控和分析查询性能,根据需要调整etl作业和查询策略也是关键。
【版权声明】:本站所有内容均来自网络,若无意侵犯到您的权利,请及时与我们联系将尽快删除相关内容!

发表回复