
大数据处理框架Storm是Twitter开源的一个分布式实时大数据处理框架,以其高性能、可靠性和可扩展性在业界被誉为实时版的Hadoop,随着数据需求的实时性越来越高,比如网站统计和金融系统等场景对数据处理的延迟容忍度越来越低,Storm的出现为满足这种需求提供了解决方案,以下是Storm的相关介绍:


1、核心概念
Spout:作为Storm中的数据源组件,Spout负责从外部系统读取数据,例如消息队列或者数据库,并将数据发布到数据流中,Spout的设计保证了Storm可以灵活地接收各类源头的数据。
Bolt:Bolt是数据处理单元,它接收来自Spout或其他Bolt的数据流,进行处理后,可以将结果发送给其他Bolt或者存储到某个地方,通过Bolt的串联,Storm能够实现复杂的数据处理逻辑。
Topology:Topology是Storm中的一个作业,包含了一系列Spouts和Bolts的网络结构,这个结构定义了数据流的处理流程和规则。
数据流:数据流是Storm中的核心,Spout和Bolt之间通过数据流进行连接,Storm提供了灵活的数据流分组方式,如随机分组、字段分组等,以满足不同的数据处理需求。
分布式协调服务:为了确保数据处理的高可靠性,Storm依赖于分布式协调服务如Zookeeper来分配和管理各个进程和节点。
数据存储:虽然Storm主要处理实时数据流,但它也可以将处理的结果存储到外部系统或数据库中,以支持进一步的数据分析和决策。
2、应用场景

实时分析:Storm适用于需要快速响应的数据分析任务,如实时广告竞价、社交网络动态分析等。
在线机器学习:由于Storm具有低延迟的特性,它非常适合于需要实时更新模型的场景,如个性化推荐系统。
连续计算:Storm可以用于构建需要持续计算并实时更新的应用,比如股票交易系统的价格监控。
分布式RPC:通过Storm,可以构建分布式远程过程调用服务,实现跨网络的服务集成。
ETL处理:Storm可以高效地处理从多个源抽取、转换和加载数据的任务,尽管它更专注于实时数据处理。
3、相关问题与解答
问题1:Storm与Hadoop的区别是什么?
答案:Storm专注于实时数据处理,提供低延迟的数据流处理能力,而Hadoop则侧重于批量处理,适合于处理不需要立即响应的大数据集。
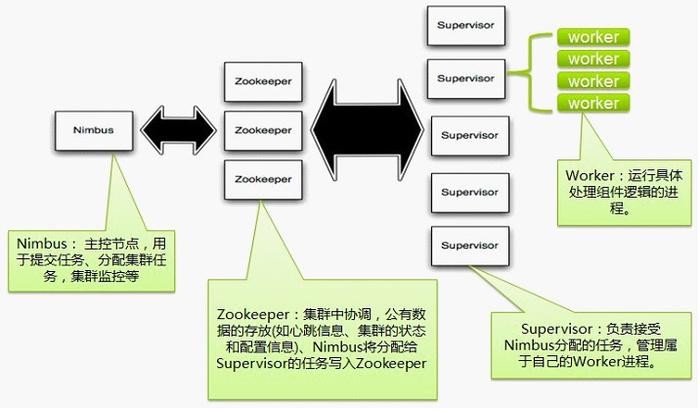
问题2:如何保证Storm处理的可靠性?
答案:Storm通过分布式协调服务如Zookeeper来实现集群管理,确保了任务分配和故障恢复的可靠性,Storm支持数据流被可靠地处理(通过消息确认机制),以及状态的持久化存储。
归纳而言,Storm作为一个分布式实时大数据处理框架,其高吞吐量、低延迟和可扩展性的特点使其在各种实时数据处理场景中得到广泛应用,通过理解其核心概念及应用场景,用户可以充分利用Storm的强大功能,实现快速、可靠的数据处理。
【版权声明】:本站所有内容均来自网络,若无意侵犯到您的权利,请及时与我们联系将尽快删除相关内容!


发表回复