
多机版多智能体深度强化学习_多终端独立版
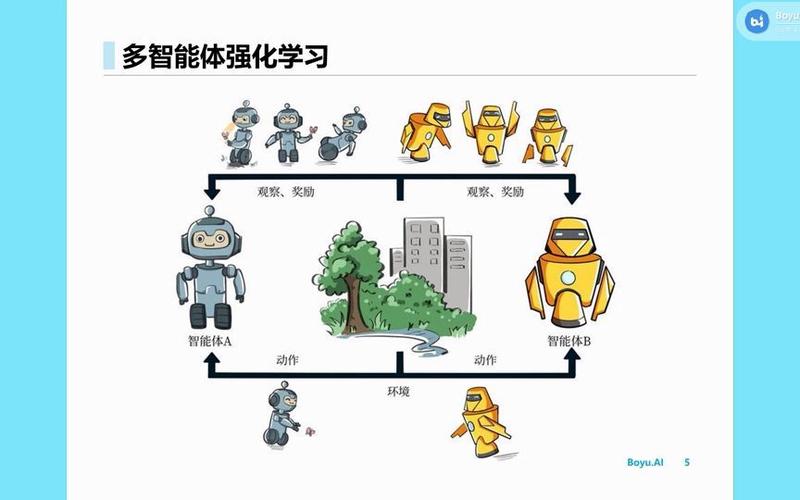

在深度学习和人工智能领域,多智能体系统(multiagent systems, mas)的研究正变得越来越重要,多智能体深度强化学习(deep reinforcement learning in multiagent systems)是一种让多个智能体在一个共享环境中通过与环境的交互进行学习的技术,在多机版多智能体深度强化学习中,每个智能体运行在不同的机器上,并通过通信网络相互协作或竞争,以完成复杂的任务。
1、系统架构设计:
系统架构通常包含以下几个关键组件:
(1)智能体(agents):每个智能体都拥有自己的策略网络,用于决策行动。
(2)环境(environment):智能体与其交互的共享环境,可以是仿真环境或者实际物理环境。
(3)通信网络(communication network):连接不同机器上智能体的媒介,负责传递状态信息、动作和奖励等数据。
(4)中央服务器(central server):可选组件,用于同步不同智能体的信息,协调学习过程。
2、算法选择与实现:
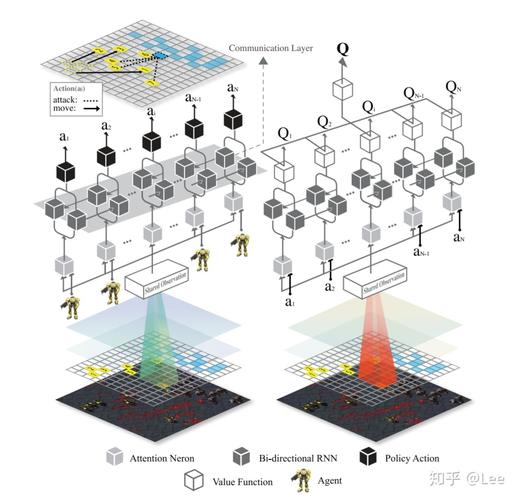
根据应用场景的不同,可以选择合适的多智能体深度强化学习算法,如:
(1)独立q学习(independent qlearning):每个智能体单独学习q值函数。
(2)多智能体演员评论家(multiagent actorcritic):每个智能体都有自己的演员网络和评论家网络。
(3)价值分解网络(value decomposition networks):将联合动作值函数分解为单个智能体的值函数之和。
3、训练与优化:
在多机环境下,训练过程需要特别考虑以下因素:
(1)并行计算:充分利用多机环境,实现智能体的并行训练。
(2)经验共享:智能体之间可以共享经验,加速学习过程。
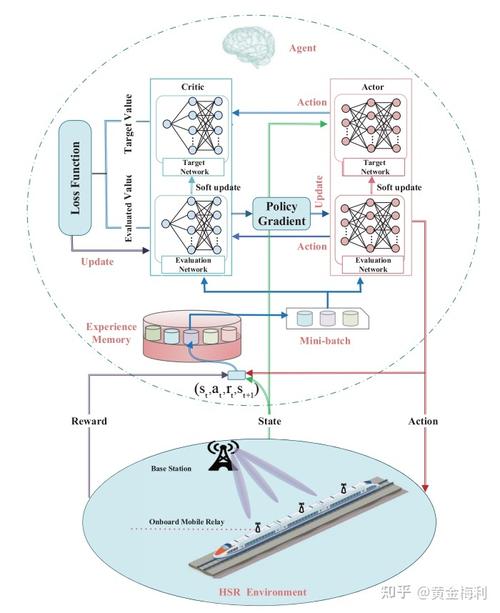
(3)通信延迟:处理由于网络通信引起的延迟问题。
(4)收敛性分析:确保多智能体系统的学习算法能够稳定收敛。
4、应用案例分析:
多机版多智能体深度强化学习可以应用于多种场景,
(1)机器人足球:多个机器人作为智能体,协同作战以进球。
(2)自动驾驶车队:车队中的每辆车作为一个智能体,共同完成运输任务。
(3)智能电网管理:多个电网节点作为智能体,协同调节电力供应和需求。
相关问题与解答:
1、问题:在多机版多智能体深度强化学习中,如何处理智能体之间的通信延迟?
解答:可以通过引入时间戳机制来标记每条消息的时间,确保智能体接收到的信息是最新的,可以使用异步通信方法来减少等待时间,提高系统的响应速度,在某些情况下,还可以采用模型预测控制(mpc)等技术来预测其他智能体的动作,从而补偿通信延迟造成的影响。
2、问题:如何确保多智能体系统中的学习算法能够稳定收敛?
解答:需要设计合适的奖励函数,以确保智能体的行为能够引导系统向期望的状态发展,可以采用经验回放(experience replay)等技术来打破智能体经验的相关性,提高学习的稳定性,还可以引入中心化的批评者(centralized critic)来评估智能体的联合行为,这有助于减少非最优纳什均衡的出现,合理的超参数调整和算法选择也是确保收敛的关键因素。
【版权声明】:本站所有内容均来自网络,若无意侵犯到您的权利,请及时与我们联系将尽快删除相关内容!


发表回复