
分布式列数据库是一种基于列式存储的分布式数据库系统,适用于大规模数据集的处理和分析,这类数据库系统设计用于高效管理大量数据,特别是在需要处理海量数据和实现快速查询的环境中,HBase是一个具有代表性的分布式列数据库。

在当今大数据时代,传统的关系型数据库在处理海量数据时常常遇到性能瓶颈,分布式列数据库的出现,为数据的存储与访问提供了一种新的解决方案,深入探讨分布式列数据库的各个方面:
1、定义与基本概念
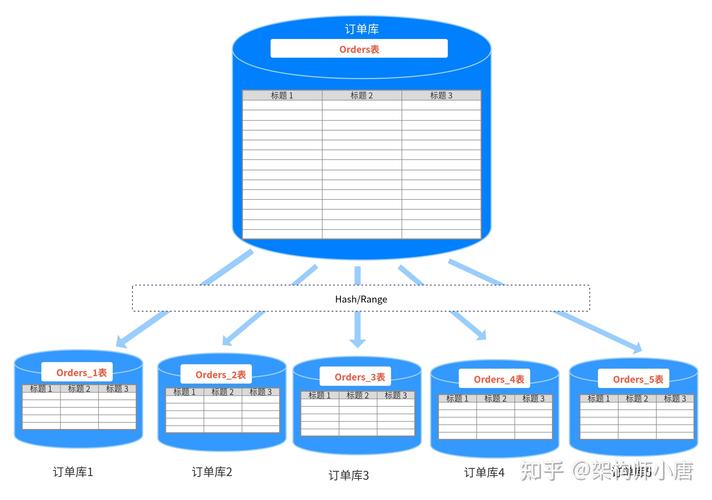
分布式系统:分布式系统是由多台计算机和硬件设备组成的系统,这些设备通过网络连接在一起,并共同工作以完成特定的任务,在分布式列数据库中,数据分散存储在多个节点上,每个节点拥有数据的一部分,而整个系统则提供一个统一的访问接口。
列式存储结构:相比行式存储,列式存储将每一列的数据聚合存储,适合于批量数据处理和即时查询,由于同一列的数据类型一致,压缩比高,能有效降低存储成本。
2、技术架构与组件
Hadoop与HDFS:Hadoop是一个开源框架,能够处理大规模数据集的分布式处理,HDFS(Hadoop Distributed File System)是Hadoop的文件系统,具有高容错性并且设计用来对应用程序进行高吞吐量的数据访问。
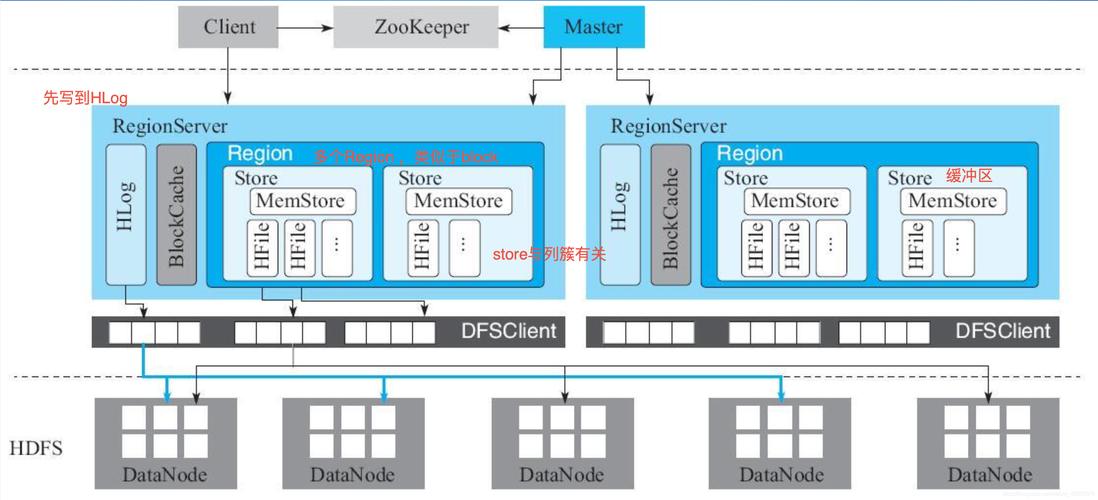
HBase架构:HBase是典型的分布式列数据库,其架构包括HMaster、RegionServer和Zookeeper等核心组件,HMaster负责元数据管理,RegionServer负责存储和管理数据,Zookeeper则用于分布式环境的协调和管理。
3、数据处理与查询优化
低延迟数据访问:分布式列数据库设计了低延迟的数据访问机制,HBase通过内部使用哈希表和存储索引,支持对较大表的快速查找,能提供数十亿记录的低延迟访问单个行记录。
批处理与实时查询:列式存储结构天然适合批处理与实时查询,这种结构避免了不必要的数据传输,只针对需要的列进行操作,大大提高了查询效率。
4、适用场景与应用实例
大数据处理:分布式列数据库擅长处理PB级别的大数据量,尤其在实时数据分析、日志处理、社交网络等数据密集型应用场景中表现出色。
超大规模数据集:对于超大规模数据集,分布式列数据库能够提供实时的随机读写功能,HBase就是为企业级应用设计的,支持海量数据的高性能随机读写。
5、设计原理与特性
列族的设计:在列式存储中,列族是一个重要概念,可以将其视为关系模型中的表,一个列族包含多行,每一行又包含多个列,这种结构使得数据组织更灵活,存储更高效。
哈希表与索引:为了实现快速数据查找,分布式列数据库内部使用哈希表来维护数据索引,这使得即使在庞大的数据集中,也能快速定位到所需数据的位置。
从数据一致性、系统扩展性和易用性方面来看,分布式列数据库通常采取多种措施保证数据在分布式环境下的一致性,系统的可扩展性也是设计的重点之一,允许系统动态添加存储节点以扩充存储容量和处理能力,而在易用性方面,分布式列数据库提供了友好的接口和文档,方便用户使用和进行二次开发。
分布式列数据库以其独特的存储方式和高效的数据处理能力,在大数据领域发挥着重要作用,通过了解其工作原理和核心组件,可以更好地利用这类数据库处理大规模的数据集,满足现代业务需求。
【版权声明】:本站所有内容均来自网络,若无意侵犯到您的权利,请及时与我们联系将尽快删除相关内容!


发表回复