
概述
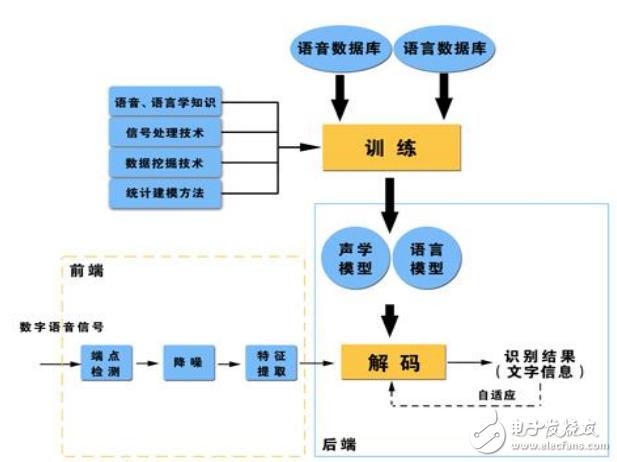

短语音识别技术是一种能够将人类语言转换为机器可读文本的技术,该技术通过分析声音信号,识别出其中的词汇和语句结构,最终生成对应的文字输出。
技术原理
音频信号处理
1、采样与量化:
采样:将声波的连续模拟信号转化为离散的数字信号。
量化:将每个采样点的振幅值映射为数字表示。
2、预加重:
增强高频成分,使信号的频谱更加平坦,便于后续处理。
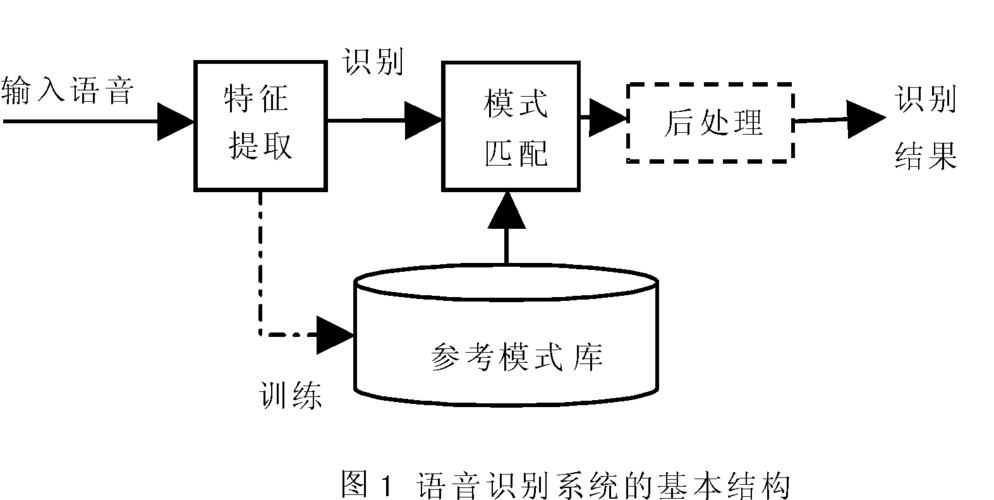
3、分帧与窗口化:
分帧:将长音频切割成短片段(帧),每帧通常包含几十毫秒的声音。
窗口化:对每帧应用窗函数,减少边界效应。
4、特征提取:
提取反映音频特性的特征向量,如梅尔频率倒谱系数(MFCC)。
模型训练
1、声学模型:
使用隐马尔可夫模型(HMM)或深度神经网络(DNN)来识别发音单元。
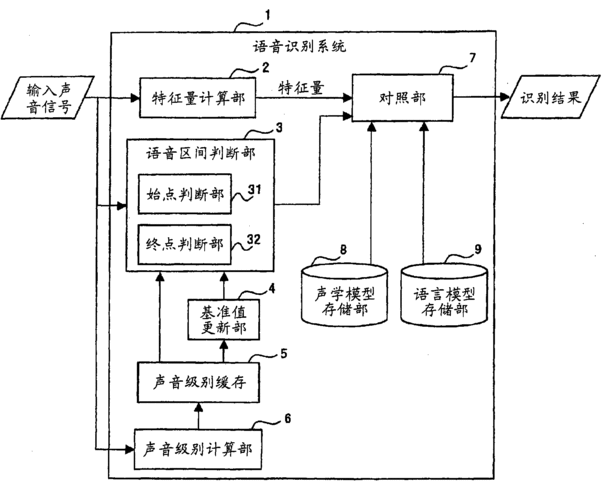
2、语言模型:
采用Ngram或循环神经网络(RNN)等方法,预测词序列的概率分布。
3、解码器:
结合声学模型和语言模型的结果,通过搜索算法找到最可能的文字序列。
系统集成
1、前端处理:
包括噪声抑制、回声消除等,提高语音信号质量。
2、后端处理:
进行语义理解、对话管理等,提升用户体验。
相关问题与解答
Q1: 短语音识别技术在嘈杂环境中的表现如何?
A1: 在嘈杂环境中,短语音识别技术的性能可能会下降,为了提高准确性,系统会采用噪声抑制技术来减少背景噪音的影响,同时使用更鲁棒的声学模型来适应复杂的声音环境。
Q2: 深度学习在短语音识别中扮演了什么角色?
A2: 深度学习在短语音识别中扮演了核心角色,它用于构建声学模型和语言模型,能够从大量数据中学习复杂的模式,显著提高了识别的准确率和效率,特别是卷积神经网络(CNN)、循环神经网络(RNN)及其变体如长短时记忆网络(LSTM)和门控循环单元(GRU)等结构的使用,极大地推动了语音识别技术的发展。
【版权声明】:本站所有内容均来自网络,若无意侵犯到您的权利,请及时与我们联系将尽快删除相关内容!

发表回复