
服务器可靠性是指服务器系统在规定条件下、规定时间内完成预定功能的能力,一个可靠的服务器系统能够确保关键业务连续性和数据完整性,减少意外停机时间,并提高用户满意度,服务器的可靠性可以通过多种方式来增强,包括但不限于硬件冗余设计、软件容错机制、系统监控与维护等措施。


服务器可靠性的关键要素
硬件冗余
硬件冗余是提高服务器可靠性的基本方法之一,通过为关键组件(如电源、硬盘、网络连接等)配置备份,可以在主设备发生故障时迅速切换到备用设备上,从而避免停机。
示例表格:常见的硬件冗余组件
| 组件 | 冗余方式 | 作用 |
| 电源供应 | 双电源或更多 | 确保电源故障不会导致服务器停机 |
| 硬盘阵列 | RAID配置 | 提供数据冗余,防止硬盘损坏导致数据丢失 |
| CPU | 多处理器或多核 | 提高处理能力,支持故障转移 |
| 网络接口 | 多网卡绑定 | 保障网络连接的稳定性 |
软件容错
软件容错机制包括操作系统和应用层面的错误检测、异常处理和恢复策略,这些机制能够在软件出现问题时采取措施,如重启服务、隔离故障进程或回滚到之前的状态。
示例表格:软件容错策略
| 策略 | 描述 |
| 自动重启 | 在服务崩溃时自动尝试重启 |
| 事务管理 | 确保数据处理的一致性和完整性 |
| 错误隔离 | 限制错误影响范围,防止全局故障 |
| 状态备份与恢复 | 定期备份系统状态,以便快速恢复 |
系统监控与维护
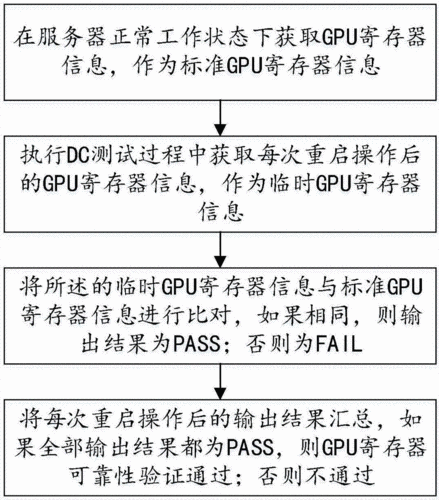
持续的系统监控可以及时发现潜在问题并采取预防措施,监控系统通常包括硬件状态监测、性能指标跟踪、安全日志审查等功能。
示例表格:系统监控要点
| 要点 | 描述 |
| 硬件健康监测 | 实时检测硬件组件状态 |
| 性能监控 | 跟踪CPU、内存、磁盘和网络的使用情况 |
| 安全审计 | 检查系统安全事件和潜在威胁 |
| 维护计划 | 定期更新和修补系统以保持最佳状态 |
灾难恢复计划
灾难恢复计划涉及创建和维护一个能够在主要数据中心发生灾难性故障时继续提供服务的备用环境,这通常包括数据备份、异地复制和快速切换机制。
示例表格:灾难恢复步骤
| 步骤 | 描述 |
| 数据备份 | 定期将数据备份到安全的存储介质 |
| 异地复制 | 在远程位置同步数据副本 |
| 切换测试 | 定期测试切换到备用环境的过程 |
| 恢复流程 | 确立在灾难发生时的详细恢复流程 |
服务器的可靠性对于保障业务连续性和数据安全至关重要,通过实施硬件冗余、软件容错、系统监控与维护以及灾难恢复计划,可以显著提高服务器系统的可靠性,可靠性的提升是一个持续的过程,需要不断地评估风险、测试系统并优化策略。
相关问题与解答
1、如何量化服务器的可靠性?
服务器的可靠性可以通过多个指标来量化,例如平均无故障时间(MTBF)、平均修复时间(MTTR)和系统可用性,MTBF越高,表明服务器运行越稳定;MTTR越低,表明故障修复速度越快;系统可用性则是综合这两个因素来衡量服务器在长期运行中的实际可用程度。
2、为什么灾难恢复计划对服务器可靠性至关重要?
灾难恢复计划对于确保在发生不可预见的灾难性事件(如自然灾害、严重硬件故障或安全攻击)时,能够快速恢复业务运营和保护数据不受损失至关重要,没有有效的灾难恢复计划,即使日常运行中的可靠性很高,一旦遇到重大灾难,也可能导致长时间的业务中断和数据丢失,给企业带来巨大的经济损失和声誉损害。
【版权声明】:本站所有内容均来自网络,若无意侵犯到您的权利,请及时与我们联系将尽快删除相关内容!


发表回复