
配置网站反爬虫防护规则,如UserAgent检测、IP访问频率限制等,有效防御恶意爬虫攻击,保障网站数据安全和正常运行。
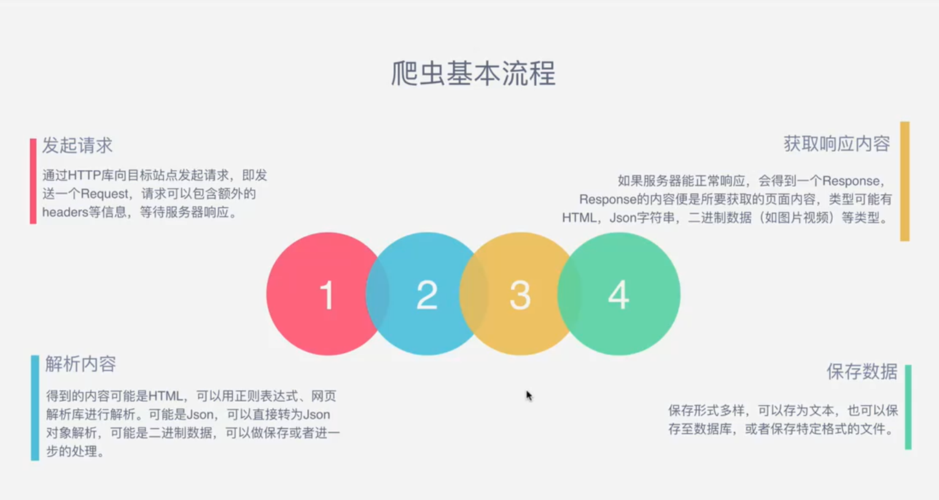
恶意爬虫是指那些未经网站所有者允许,自动访问并爬取网站内容的机器人程序,这些爬虫可能对网站的服务器造成负载压力,导致网站崩溃或响应速度变慢,为了保护网站免受恶意爬虫的攻击,网站管理员可以采取一些反爬虫措施来配置防护规则。

(图片来源网络,侵删)
1. 使用UserAgent识别和过滤爬虫
UserAgent是浏览器发送给服务器的请求头信息,用于标识用户代理(即浏览器)的类型和版本,通过检查UserAgent,可以识别出是否为爬虫程序。
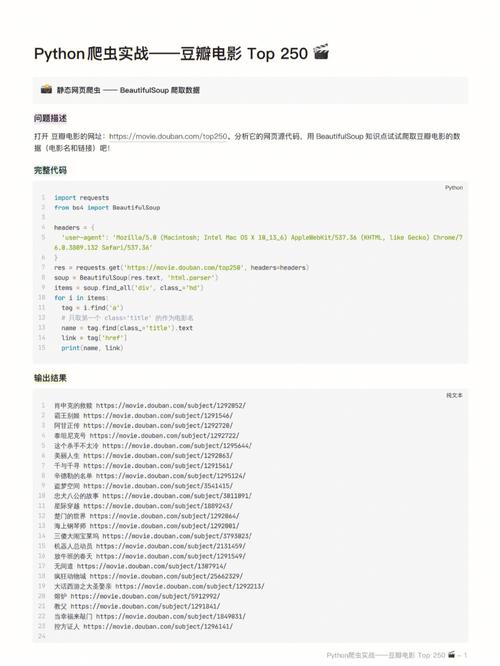
from flask import Flask, request
app = Flask(__name__)
@app.route('/')
def index():
user_agent = request.headers.get('UserAgent')
if 'bot' in user_agent:
return "您是一个爬虫程序"
else:
return "欢迎访问我们的网站" 2. 使用验证码进行人机验证
验证码是一种常见的反爬虫手段,要求用户输入图片中显示的数字或字符,以确认其为真实人类用户。
在Python中可以使用第三方库如captcha生成验证码图片:
from captcha.image import ImageCaptcha
import random
import string
from flask import Flask, render_template, request, session
app = Flask(__name__)
app.secret_key = 'your_secret_key'
@app.route('/captcha')
def generate_captcha():
image = ImageCaptcha()
captcha_text = ''.join(random.sample(string.ascii_uppercase + string.digits, 4))
session['captcha_text'] = captcha_text
return image.generate(captcha_text) 在需要验证的地方,检查用户输入的验证码是否正确:
if request.form.get('captcha') != session['captcha_text']:
return "验证码错误" 3. 设置访问频率限制
通过限制每个IP地址在单位时间内的访问次数,可以有效防止恶意爬虫的频繁访问,这可以通过Flask框架中的before_request装饰器实现:
(图片来源网络,侵删)
from flask import Flask, request, g
from functools import wraps
import time
app = Flask(__name__)
visit_count = {} # 存储每个IP地址的访问次数和时间戳
def limit_visits(max_per_minute):
def decorator(func):
@wraps(func)
def wrapper(*args, **kwargs):
ip = request.remote_addr
now = int(time.time())
visit_count[ip] = (now visit_count[ip][1], visit_count[ip][0] + 1) if ip in visit_count else (now, 1)
# 如果超过最大访问次数,则返回错误信息
if visit_count[ip][0] > max_per_minute:
return "访问过于频繁,请稍后再试"
return func(*args, **kwargs)
return wrapper
return decorator 然后在需要限制访问频率的路由上使用该装饰器:
@app.route('/')
@limit_visits(60) # 每分钟最多访问60次
def index():
return "欢迎访问我们的网站" 问题1:如何防止搜索引擎爬虫被误判为恶意爬虫?
答:为了防止搜索引擎爬虫被误判为恶意爬虫,可以在网站的robots.txt文件中添加相应的规则,允许搜索引擎爬虫的访问,还可以通过分析UserAgent来判断是否为搜索引擎爬虫,如果是则放行,百度的UserAgent通常包含"Baiduspider"关键字。
(图片来源网络,侵删)
【版权声明】:本站所有内容均来自网络,若无意侵犯到您的权利,请及时与我们联系将尽快删除相关内容!


发表回复