
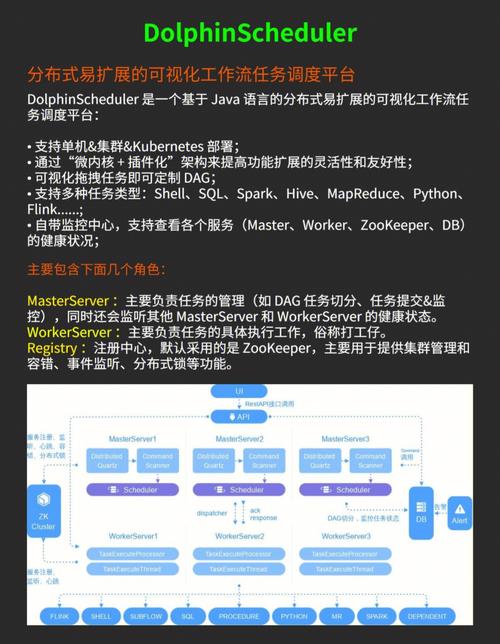

在当今数据驱动的世界中,大数据技术正迅速发展,并成为企业决策、运营优化和创新的关键驱动力,随着这一趋势的发展,众多开源解决方案应运而生,为组织提供了处理和分析海量数据集的能力,这些开源工具不仅降低了成本门槛,还促进了技术的快速迭代和社区的共同进步,以下是一些流行的大数据开源解决方案及其相关开源声明的概述。
apache hadoop
apache hadoop是一个开源框架,它允许分布式处理大数据集在集群中的存储和计算,hadoop生态系统包括多个项目,如hdfs(hadoop分布式文件系统)、mapreduce等。
开源声明:
apache hadoop遵循apache license 2.0,这是一个允许用户自由使用、修改和分发软件的许可协议,该许可证要求保留原始版权声明和许可通知,并要求任何修改过或衍生的作品也以相同的许可证发布。
apache spark
apache spark是一个开源集群计算系统,提供了快速的数据处理能力,尤其擅长大规模数据处理和机器学习任务。
开源声明:

与hadoop类似,apache spark也是基于apache license 2.0发布的,这意味着用户可以免费使用spark进行开发和部署,同时需要遵守许可证中的规定。
apache kafka
apache kafka是一个分布式流处理平台,常用于构建实时数据管道和流应用程序,它支持高吞吐量、可扩展性以及低延迟的数据传递。
开源声明:
apache kafka同样遵循apache license 2.0,允许用户在满足许可证条款的情况下自由地使用、修改和分发软件。
apache flink
apache flink是一个框架和分布式处理引擎,用于在各种环境中以高效率执行有状态的流处理应用。
开源声明:
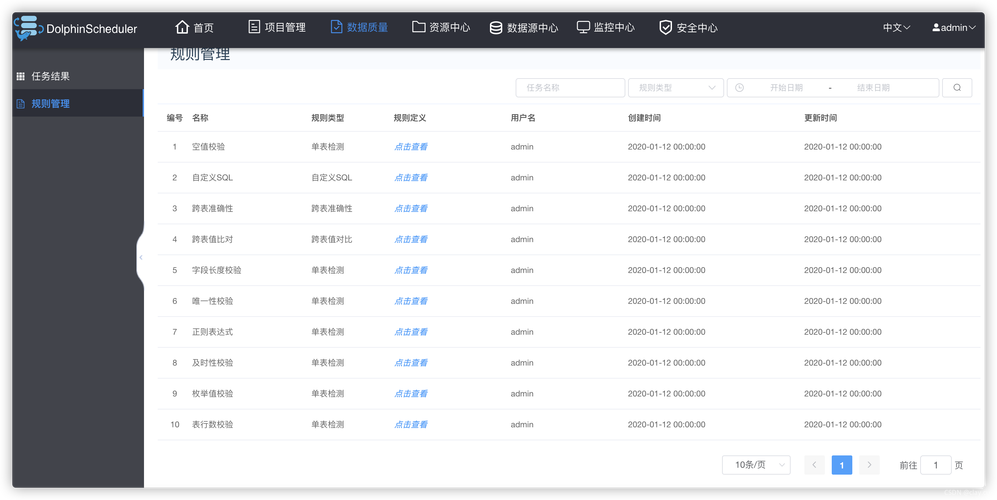
flink项目也是在apache license 2.0下发布的,这保证了其在商业和非商业用途下的开放性和灵活性。
相关问题与解答
问题1:如果我在一个商业项目中使用了这些开源解决方案,我需要支付版权费吗?
答案:不需要,所有提到的开源解决方案都是在apache license 2.0下发布的,该许可证允许你在遵守其规定的前提下免费使用这些软件进行开发和部署,无需支付任何费用。
问题2:我能否将开源解决方案作为专有软件销售?
答案:可以,但有条件,根据apache license 2.0,你可以将开源软件作为你的产品的一部分销售,但是你必须遵守许可证的要求,例如保留原始版权声明和许可通知,并且任何修改或衍生作品也必须以相同的许可证发布,你还需要确保你的客户有权访问源代码。
【版权声明】:本站所有内容均来自网络,若无意侵犯到您的权利,请及时与我们联系将尽快删除相关内容!


发表回复