
分库分表是数据库水平切分的一种策略,主要用于解决单一数据库无法承受较大数据量和高并发访问的问题,当一个数据库被设计为承担超出其物理限制的数据量时,就需要进行扩容操作,以下是关于分库分表的详细解释以及扩容过程:
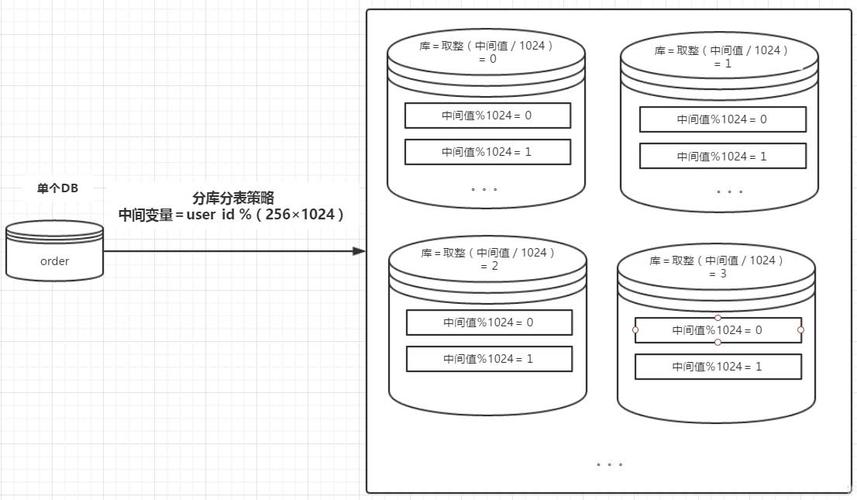

什么是分库分表?
分库指的是将数据分散到多个数据库实例中,每个实例称为一个分库,它们可以位于同一台服务器上或分布在不同服务器上。
分表则是将一张大表拆分成多张小表,这些小表的结构相同但数据不同,每张小表被称为一个分表。
为什么要进行分库分表?
1、提高性能:通过减少单个数据库或表的负载,可以提高查询效率和响应速度。
2、增强可扩展性:随着业务的增长,可以通过增加更多的数据库或表来横向扩展系统。
3、提升稳定性:分布式系统能够更好地应对硬件故障,避免单点故障带来的影响。
4、优化资源使用:可以根据不同业务需求合理分配资源,比如IO密集型和CPU密集型的业务分开处理。
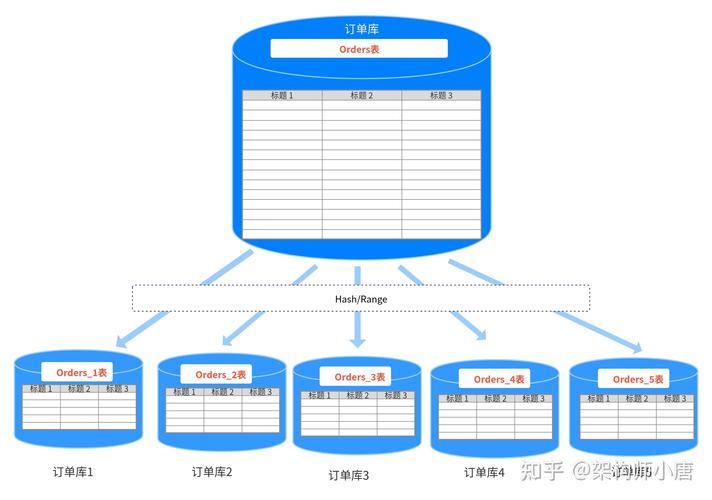
分库分表的策略
分库分表的策略通常包括范围分片、哈希分片、列表分片等,选择合适的策略取决于具体的业务场景和需求。
范围分片:根据某个字段的范围将数据分散到不同的数据库或表中。
哈希分片:通过对特定字段的哈希值进行计算来决定数据存放的位置。
列表分片:预先定义好一个列表,根据列表的值将数据分布到不同的数据库或表中。
扩容过程
扩容通常涉及到以下几个步骤:
1、评估需求:分析当前的性能瓶颈和未来的数据增长趋势。
2、选择策略:确定采用哪种分库分表策略。
3、数据迁移:将现有的数据按照新的分库分表规则重新分配。
4、修改应用:更新应用程序中的数据库连接和查询逻辑,以适应新的分库分表结构。
5、测试验证:在生产环境部署前进行充分的测试,确保数据的一致性和系统的稳定运行。
6、监控调优:扩容后监控系统性能,进行必要的调优。
扩容示例表格
| 步骤 | 描述 | 注意事项 |
| 1. 评估需求 | 分析系统负载和数据增长趋势 | 确保评估准确,避免过早或过晚扩容 |
| 2. 选择策略 | 确定分库或分表的具体策略 | 根据业务特点选择合适的策略 |
| 3. 数据迁移 | 按照新规则迁移现有数据 | 保证数据迁移过程中的一致性和完整性 |
| 4. 修改应用 | 更新应用代码以适配新的数据库结构 | 注意事务管理及跨库查询的处理 |
| 5. 测试验证 | 在类生产环境中进行全面测试 | 模拟真实负载,确保系统稳定性 |
| 6. 监控调优 | 观察并优化系统性能 | 持续监控,及时调整配置 |
相关问答
Q1: 分库分表后如何保证事务的一致性?
A1: 分库分表后的事务处理比较复杂,可以采用分布式事务管理器如XA协议或者两阶段提交来保证一致性,还可以考虑最终一致性方案,通过补偿事务来处理不一致的情况。
Q2: 扩容后如何对数据进行备份和恢复?
A2: 扩容后的数据备份需要分别对每个数据库实例进行,可以使用定时任务对每个数据库进行全量或增量备份,并将备份数据存储在安全的地方,恢复时,需要根据备份策略逐个恢复数据库实例。
【版权声明】:本站所有内容均来自网络,若无意侵犯到您的权利,请及时与我们联系将尽快删除相关内容!


发表回复