
电影网站采集教程通常指的是使用特定的工具或程序来抓取电影网站上的数据,比如电影名称、演员、导演、上映日期、评分等信息,以下是一份详细的电影网站数据采集教程,包括使用Python编程语言和一些常用库的步骤:

准备工作
1、安装Python(如果尚未安装):访问 https://www.python.org/downloads/ 下载并安装Python。
2、安装所需库:
请求库(用于发送HTTP请求):pip install requests
解析库(用于解析HTML文档):pip install beautifulsoup4
动态编程库(用于处理JavaScript加载的内容):pip install selenium
Web驱动(用于Selenium,如ChromeDriver):从 https://sites.google.com/a/chromium.org/chromedriver/downloads 下载适合你的浏览器版本的驱动程序。
步骤一:了解目标网站结构
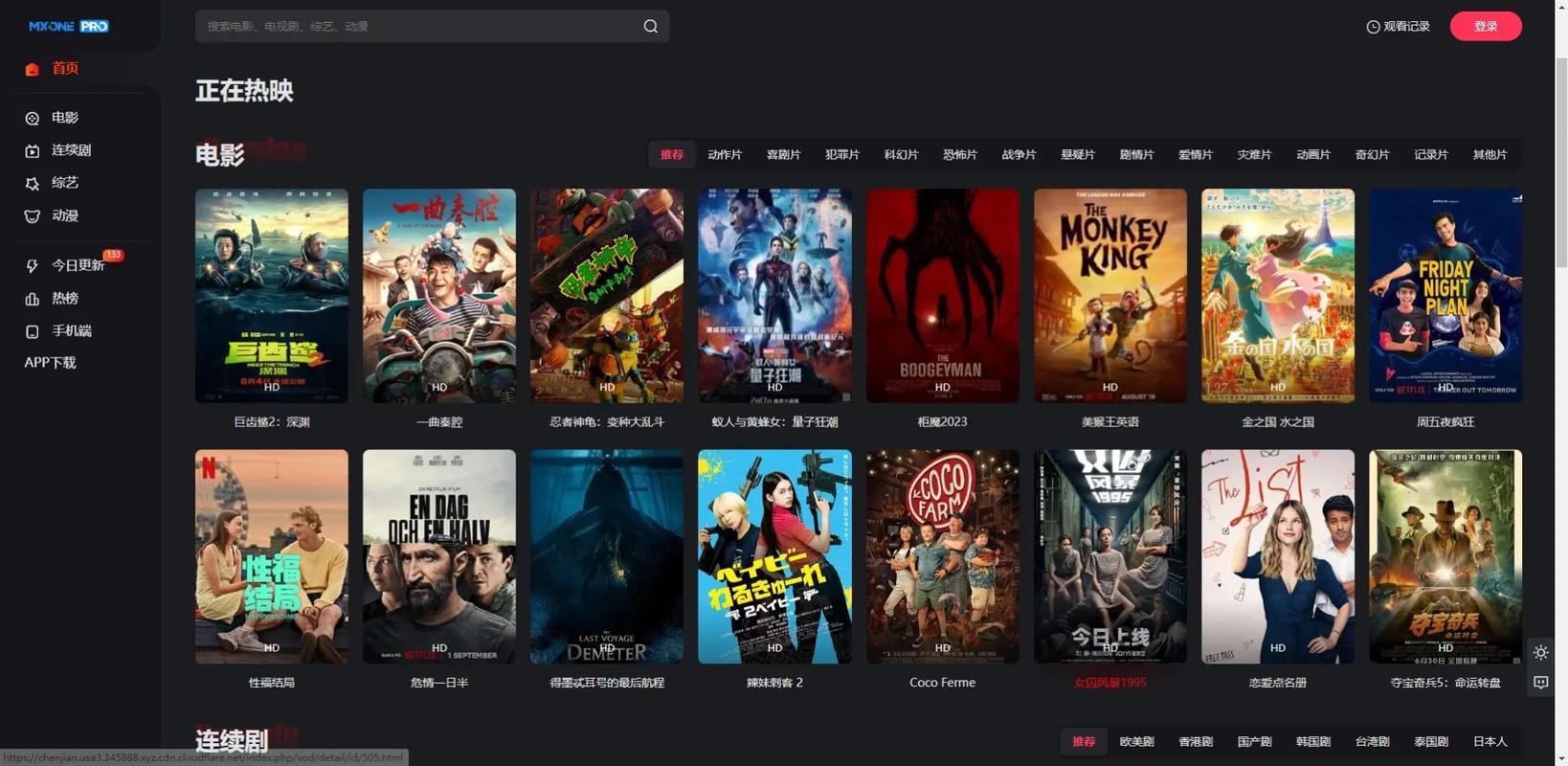
1、打开目标电影网站。
2、检查页面源代码(通常可以通过浏览器的“查看页面源代码”功能查看)。
3、确定要采集的数据在源代码中的位置和结构。
步骤二:编写代码采集数据
1、导入所需库:
from bs4 import BeautifulSoup import requests from selenium import webdriver from selenium.webdriver.chrome.service import Service from webdriver_manager.chrome import ChromeDriverManager from selenium.webdriver.common.by import By import time
2、配置Selenium:
设置webdriver的路径 service = Service(ChromeDriverManager().install()) 创建webdriver对象 driver = webdriver.Chrome(service=service)
3、获取网页内容:
url = "目标电影网站的URL" # 替换成实际的电影网站URL driver.get(url) time.sleep(5) # 等待页面加载完成,包括可能的JavaScript执行 html_content = driver.page_source
4、解析网页内容:
soup = BeautifulSoup(html_content, 'html.parser')
根据网页结构定位数据,例如电影名称
movie_titles = soup.find_all('div', class_='movietitle') # 根据实际情况修改
for title in movie_titles:
print(title.text) 5、采集其他数据,如演员、导演等,按照类似的方式定位和提取。
6、保存数据:
with open('movies.txt', 'w') as f:
for movie in movies: # 假设movies是包含电影信息的列表
f.write(f"{movie['title']} {movie['director']} {movie['actors']}
") 步骤三:运行脚本并收集数据
1、运行Python脚本。
2、监控输出以检查是否有错误。
3、确认数据被正确保存。
注意事项
1、遵守法律法规:确保你有权采集该网站上的数据,并且不违反版权或隐私法律。
2、尊重robots.txt:网站可能通过robots.txt文件禁止某些内容的采集,请先检查该文件。
3、用户代理:有些网站可能会屏蔽默认的用户代理(UserAgent),你可能需要设置一个真实的浏览器用户代理。
4、异常处理:增加异常处理逻辑以应对网络问题或数据解析问题。
5、频率控制:避免频繁请求导致对服务器造成压力或被封IP。
步骤仅为一般指导,每个网站的布局和结构都不同,因此具体的采集代码会有所不同,需要根据实际的目标网站进行适当的调整。
【版权声明】:本站所有内容均来自网络,若无意侵犯到您的权利,请及时与我们联系将尽快删除相关内容!


发表回复