
在分布式数据库中,事务的处理是保障数据一致性和可靠性的关键机制。
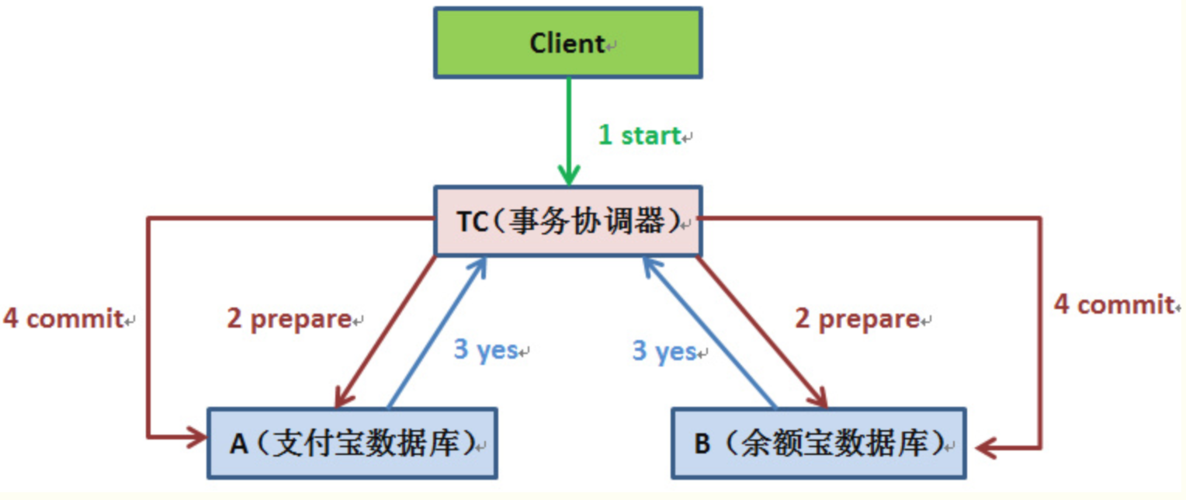

分布式数据库事务通常涉及多个数据库实例,这些实例可能分布在不同的物理位置上,在这种环境下,一个事务可能需要在多个数据库节点上同时执行,与单体架构中的事务管理相比,这大大增加了复杂性,从Seata的分布式事务框架来看,它通过支持XA协议的资源来管理分支事务,显示了分布式事务处理的一种标准方式,下面将从不同方面展开分析分布式数据库事务:
1、定义:在分布式数据库中,事务是一个或多个操作的序列,这个序列被视为一个不可分割的执行单元,事务在分布式数据库中的作用与在单一数据库中的作用相同,即保证一系列的操作能够全部成功或者全部失败,这样可以避免数据状态的不一致,确保数据的完整性。
2、属性:分布式数据库事务也遵循ACID特性,原子性保证了事务内的操作要么全部成功,要么全部不做;一致性确保事务从一个合法的状态转移到另一个合法的状态;隔离性指防止多个事务同时执行时互相干扰;持久性保证了一旦事务提交,其结果就是永久性的,这些特性共同维护了分布式数据库中事务的正确性和可靠性。
3、类型:分布式事务有多种类型,如扁平事务、带有保存点的扁平事务、链式事务、嵌套事务和分布式事务,这些类型根据事务的结构和复杂性不同而有所区分,每种类型都有其特定的应用场景和优势。
4、挑战:分布式系统中的事务管理面临数据一致性、网络延迟、节点故障等多种挑战,为了处理这些问题,分布式数据库通常实现了如两阶段提交(2PC)等复杂的事务管理协议,以保证跨节点的事务可以正确且高效地执行。
值得一提的是,分布式数据库的事务管理需要有恢复机制,当系统出现部分故障时,能保证事务的恢复和数据的一致性,分布式事务还需要处理并发控制,避免因多个事务并行执行而带来的数据冲突和不一致问题。
在了解分布式数据库事务的特点和挑战后,还需注意以下两点:
网络稳定性:分布式事务的处理高度依赖于稳定的网络连接,网络波动或中断可能会影响事务的成功率。
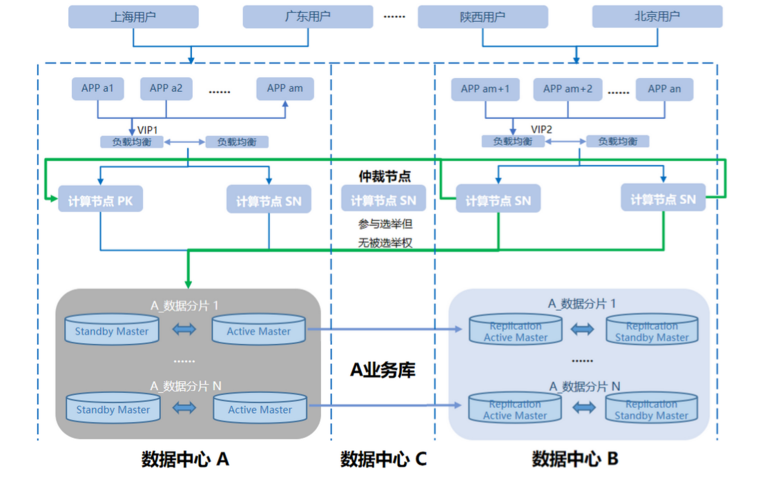
数据同步策略:如何有效地同步各个节点之间的数据,确保所有节点的数据状态一致,是设计分布式数据库时必须考虑的问题。
归纳而言,分布式数据库事务是分布式系统中一个关键而复杂的组成部分,理解其基本定义、属性、面临的挑战及应对策略,对于设计和处理大规模分布式系统中的数据操作具有重要意义,在实际应用中,选择合适的事务管理策略和技术支持,能够有效提高系统的可靠性和数据的准确性。
【版权声明】:本站所有内容均来自网络,若无意侵犯到您的权利,请及时与我们联系将尽快删除相关内容!


发表回复