
1、请解释一下什么是Repartition?

Repartition是Spark中对RDD进行重新分区的操作,它可以将一个RDD的数据分散到多个Partition中,以便在集群中并行处理,Repartition操作通常用于优化数据的分布,提高计算效率。
2、Repartition的作用是什么?
Repartition的主要作用有以下几点:
平衡数据:当某个Partition的数据量过大时,可以通过Repartition操作将其数据分散到其他Partition中,以实现数据的均衡分布。
并行度调整:通过调整Partition的数量,可以控制任务的并行度,从而提高计算效率。
数据迁移:在分布式系统中,可以通过Repartition操作将数据从一个节点迁移到另一个节点。
3、Repartition与Coalesce、Sort的区别是什么?
Repartition:重新分区,会触发数据的shuffle操作,可能导致性能问题,适用于需要改变Partition数量的情况。
Coalesce:合并Partition,不会触发数据的shuffle操作,但会增加每个Partition的数据量,适用于减少Partition数量以提高计算效率的情况。
Sort:对RDD进行排序,会触发数据的shuffle操作,适用于需要对数据进行排序的情况。
4、Repartition操作会触发哪些操作?
Repartition操作会触发以下操作:
Shuffle:将数据从原Partition中移动到新的Partition中,这可能会导致性能问题。
Copy:将数据从原节点复制到新节点。
5、如何避免Repartition操作带来的性能问题?
为了避免Repartition操作带来的性能问题,可以采取以下策略:
尽量减少不必要的Repartition操作。
使用合适的Partition数量,避免Partition过多或过少。
在执行Repartition操作之前,先执行coalesce操作,尽量合并小Partition。
在执行Repartition操作之后,尽量使用cache或persist操作,将数据缓存到内存中,避免重复计算。
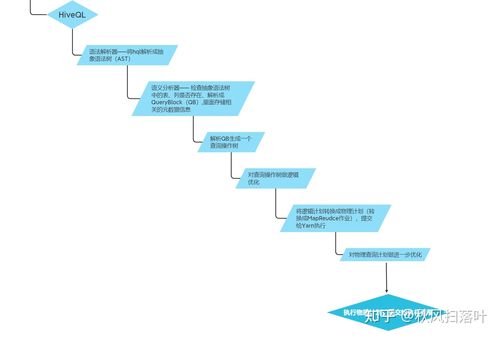
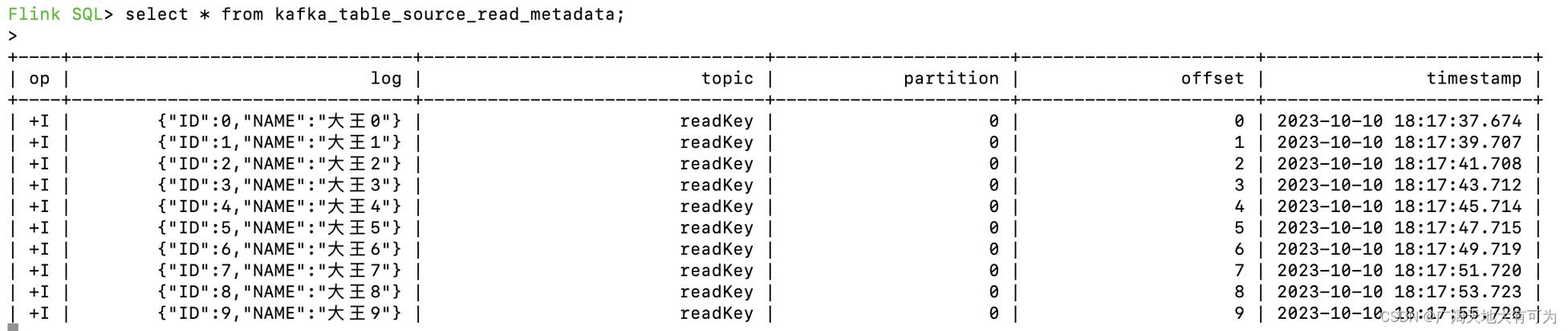
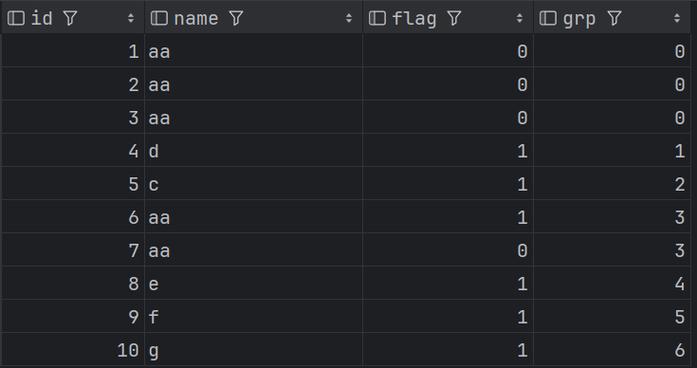
在处理大数据面试题时,若需要将“Repartition时有部分Partition没数据”的情况制作为一个介绍,我们可以将这种场景抽象为以下的结构:
| Partition ID | 数据条数 | 状态描述 |
| 1 | 0 | 无数据 |
| 2 | 500 | 正常 |
| 3 | 0 | 无数据 |
| 4 | 1000 | 正常 |
| … | … | … |
| N | 300 | 正常(最后一个) |
以下是对介绍中每一列的说明:
Partition ID: 分区的标识符,通常是一个整数。
数据条数: 当前分区中包含的数据条数,在这个场景中,有些partition的数据条数为0,表示没有数据。
状态描述: 描述每个分区的状态,对于没有数据的分区,标记为“无数据”,而对于有数据的分区,则标记为“正常”。
这个介绍假设了在执行了repartition操作之后,一部分分区包含数据,而另一部分则没有,在实际的面试中,面试官可能会要求你解释为什么会发生这种情况,以及如何解决这类问题,以下是可能的跟进问题和答案:
1、为什么会发生这种情况?
– 可能是由于数据源本身就不均匀,导致在重新分区时,某些分区的数据量很小甚至没有数据。
– 或者是在repartition操作之前的数据处理步骤中,某些数据被过滤掉了,从而导致部分分区数据丢失。
2、如何解决这种情况?
– 可以在repartition之前执行一个过滤和合并的步骤,以确保每个分区都有足够的数据。
– 使用不同的分区策略,例如基于数据键的范围分区,以期望获得更均匀的数据分布。
– 在某些情况下,如果数据不均匀是可接受的,可以选择在后续处理中忽略这个问题。
在面试时不仅要提供介绍,还要展示你对于问题的深入理解和解决方案的能力。
【版权声明】:本站所有内容均来自网络,若无意侵犯到您的权利,请及时与我们联系将尽快删除相关内容!


发表回复