
大数据的分类是数据挖掘领域中的一个核心议题,涉及到多种算法和方法,在当前信息化快速发展的背景下,大数据的分类技术帮助企业和组织从庞大的数据集中提取有价值的信息,支持决策制定,以下是一些主要的大数据处理方式和其具体实施方法:
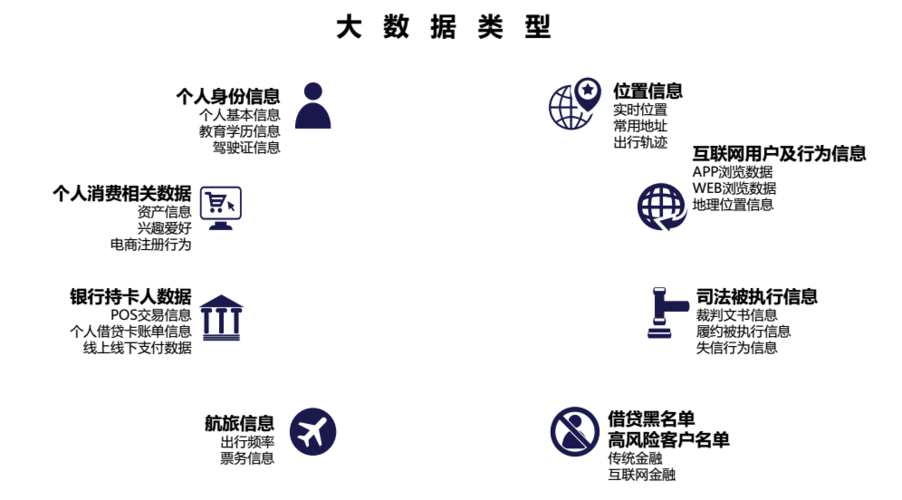

分类方法
1. 分类决策树
原理:分类决策树通过计算信息增益、信息增益比或基尼系数选择分裂特征,递归地构建树模型。
应用场景:适用于具有类别标签的训练数据集,可处理特征关联性和非线性问题。
2. K近邻(KNN)算法
原理:通过计算待分类数据点与已标记数据点的距离,选取距离最近的K个点,以多数投票决定新数据点的类别。
应用场景:适合数据集中的每个类别样本数较为平均的情况,对异常值敏感。
回归分析
原理:通过建立数学模型预测连续值,常用线性回归、逻辑回归等。
应用场景:常用于金融分析、市场预测等领域,需要预测具体数值的场景。
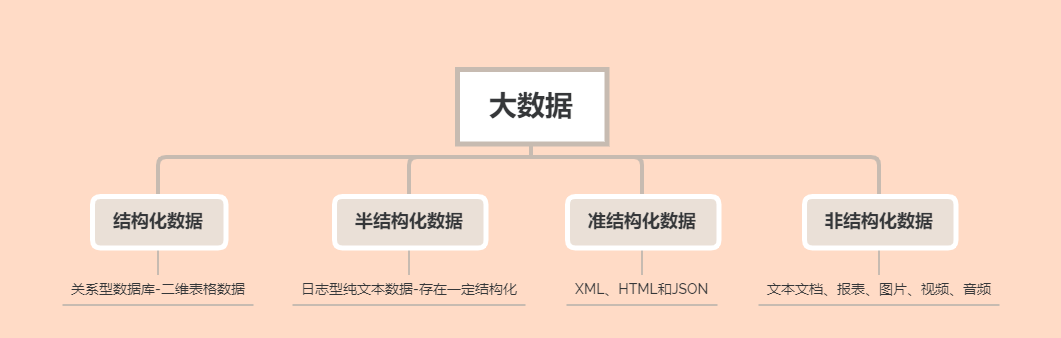
聚类分析
原理:将数据集合分为多个组,使得同组内的数据相似度高,不同组之间的相似度低。
应用场景:广泛应用于客户细分、社交网络分析等。
关联规则
原理:发现数据项之间的有意义关系,如市场篮分析。
应用场景:常用于零售行业,通过顾客购买模式推荐商品。
神经网络方法
原理:模拟人脑神经元连接,通过大量节点之间的相互作用进行数据处理和学习。
应用场景:图像和语音识别、自然语言处理等复杂模式识别任务。
Web数据挖掘
原理:从网页内容及使用记录中提取信息。
应用场景:搜索引擎优化、用户行为分析等。
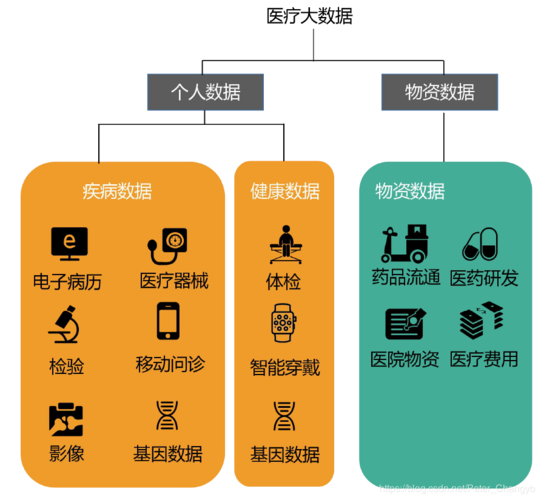
相关问题与解答
Q1: 如何选择最适合的大数据分类方法?
Q2: 大数据分类的准确性如何提升?
Q1: 如何选择最适合的大数据分类方法?
答: 选择最合适的大数据分类方法需要考虑数据的类型、分布以及最终的应用目标,如果目标是预测数值型数据,可能首选回归分析;若需处理图像识别问题,则神经网络可能是更好的选择,还需考虑算法的复杂度和可解释性。
Q2: 大数据分类的准确性如何提升?
答: 提升分类准确性可以从以下几个方面着手:提高数据质量,包括数据清洗和预处理;选择合适的特征和分类算法;使用交叉验证等技术评估模型性能;调整模型参数,进行模型优化。
【版权声明】:本站所有内容均来自网络,若无意侵犯到您的权利,请及时与我们联系将尽快删除相关内容!


发表回复