
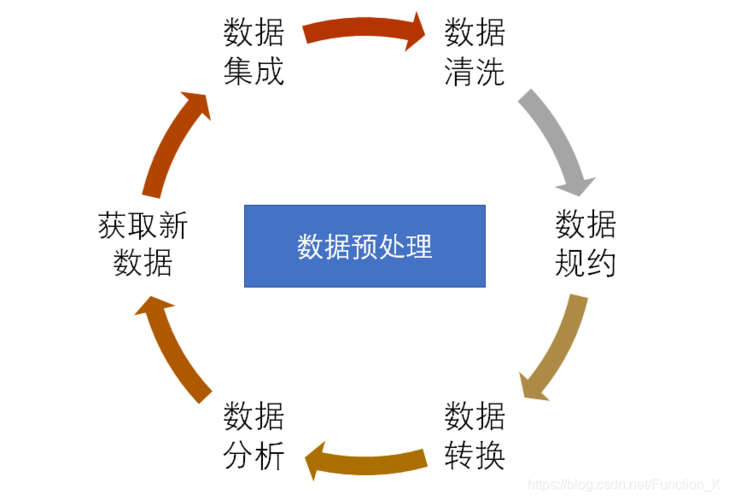
大数据的预处理方法包括数据清洗、数据集成、数据规约和数据变换,在处理大数据时,这些步骤是至关重要的,它们确保了数据质量和一致性,从而提高了数据分析和建模的准确性和效率,以下是对它们的相关介绍:
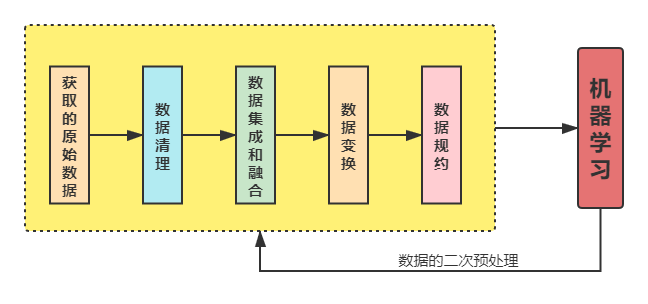

1、数据清洗
缺失值处理:处理数据中的缺失值,可以采用填补、删除或忽略记录等策略,填补缺失值可以通过均值、中位数或基于预测模型的方法来实现。
噪声数据处理:噪声数据是指数据中的随机错误或方差,可以通过平滑技术或聚类方法来识别和处理,使用回归分析或基于聚类的方法来平滑数据点。
离群点处理:离群点是数据中与大多数数据明显不同的点,可能由测量误差或异常行为产生,处理离群点的方法包括删除或使用统计方法(如基于距离的方法或基于密度的方法)来检测和处理它们。
不一致数据处理:纠正数据中的不一致,如单位不同、格式不匹配等,这通常涉及到标准化数据格式和单位转换。
2、数据集成
来源不同的数据整合:将来自不同来源的数据整合在一起,需要解决数据冗余和不一致问题,这涉及到识别不同数据源之间的关系,以及合并这些数据以形成一个一致的数据集。
实体识别问题:在数据集成过程中,需要解决实体识别问题,即确定来自不同数据源的哪些数据表示同一个实体。
3、数据规约
特征选择:通过选择对模型预测最有用的特征子集,减少数据集中的特征数量,这可以降低数据的复杂性和存储需求,同时提高模型的性能。
特征提取:通过构造新的特征来转换数据,这些新特征可以捕获数据的重要信息并降低数据的维度。
4、数据变换
归一化和标准化:将数据转换为标准形式,使其具有零均值和单位方差(标准化)或将其缩放到特定的范围(归一化),这对于许多机器学习算法来说是必要的,因为它们对数据的尺度敏感。
对数变换:对数据进行对数变换,以便更好地处理具有偏斜分布的数据。
离散化:将连续数据转换为离散形式,以便在某些类型的机器学习模型中使用。
大数据预处理是确保数据分析和建模成功的关键环节,通过适当的数据清洗、数据集成、数据规约和数据变换,可以提高数据质量,从而提升最终模型的性能和准确性。
【版权声明】:本站所有内容均来自网络,若无意侵犯到您的权利,请及时与我们联系将尽快删除相关内容!


发表回复