
大数据与海量存储
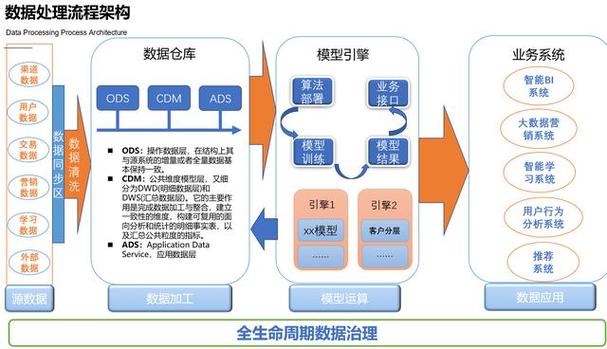

数据存储技术概述
在大数据时代,数据的存储和管理变得尤为重要,随着数据量的飞速增长,传统的存储系统已无法满足需求,因此出现了多种新型的海量数据存储解决方案,这些方案包括但不限于分布式文件系统(如Hadoop的HDFS)、云存储服务(如Amazon S3、Google Cloud Storage)和NoSQL数据库(如MongoDB、Cassandra)。
关键特性
1、可扩展性:能够随着数据量的增长而增加存储容量,无需频繁更换基础设施。
2、可靠性:通过数据备份和容错机制保证数据的完整性和可用性。
3、性能:支持高并发访问和快速数据处理的能力。
4、成本效益:在满足上述要求的同时,还需考虑成本控制,以实现经济效益。
分布式文件系统
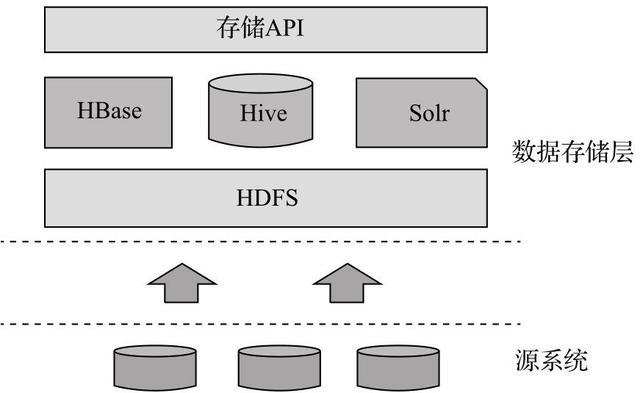
HDFS:Hadoop Distributed File System是专为处理大规模数据集而设计的,它通过将数据分块并分布在多个节点上来实现高效存储和访问。
架构:包含NameNode(管理元数据)和DataNode(存储数据块)两种角色。
云存储服务
Amazon S3:提供对象存储,可用于存储和检索任意类型的非结构化数据。
优势:高度可扩展、可靠、安全,且无需管理硬件。
NoSQL数据库
MongoDB:文档型数据库,适合处理大量的非结构化或半结构化数据。
特点:灵活的数据模型、易于扩展和高性能。

数据存储策略
热数据与冷数据:根据访问频率对数据进行分类,热数据存放在高速存储中,冷数据迁移到成本较低的存储介质。
数据去重和压缩:减少存储空间需求,提高存储效率。
安全性与合规性
加密:确保数据在传输和静态时的安全。
访问控制:限制数据访问权限,防止未授权访问。
合规性:遵守相关法律和行业标准,如GDPR、HIPAA等。
相关问题与解答
Q1: 大数据存储与传统数据存储有何不同?
A1: 大数据存储面临的挑战包括处理极高的数据量、多样性和速度,与传统数据存储相比,大数据存储需要更高的可扩展性、更强的并行处理能力以及更复杂的数据管理技术,传统数据存储通常针对结构化数据设计,而大数据存储则需处理结构化、半结构化和非结构化数据。
Q2: 如何选择合适的大数据存储解决方案?
A2: 选择合适的大数据存储解决方案时,应考虑以下因素:
数据类型和大小:确定数据的性质和规模,选择能够有效处理这些数据的存储系统。
预算:根据预算选择最合适的存储解决方案,同时考虑长期的运营成本。
性能需求:评估读写速度、延迟和并发用户数等性能指标。
可扩展性:确保所选的解决方案能够随着数据增长而扩展,无需重大更改。
安全性和合规性:确保解决方案符合行业安全标准和法律法规要求。
【版权声明】:本站所有内容均来自网络,若无意侵犯到您的权利,请及时与我们联系将尽快删除相关内容!


发表回复