
二叉堆和决策树回归是两个不同的概念,它们在数据结构与机器学习领域分别扮演着重要的角色,下面将分别介绍这两种结构,并探讨它们在实际应用中的相关性。
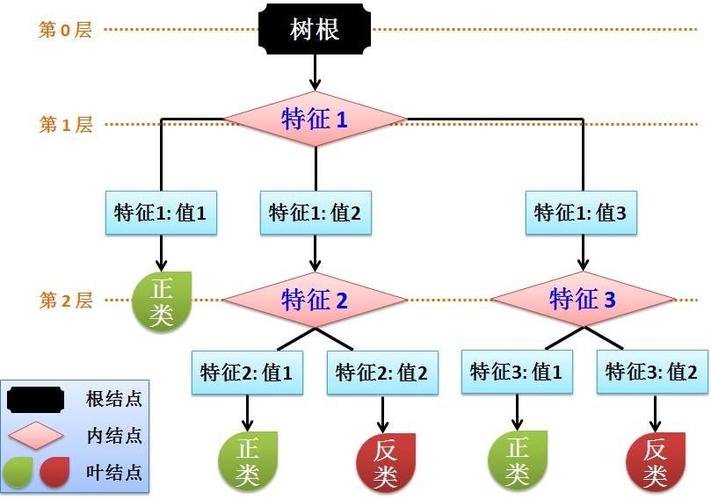

二叉堆 (Binary Heap)
二叉堆是一种特殊的完全二叉树,主要用来实现优先队列的数据结构,在二叉堆中,每个节点都大于等于(最大堆)或小于等于(最小堆)其子节点的值,这种性质使得堆顶元素总是最大(最大堆)或最小(最小堆)。
特性
完全二叉树:除最后一层外,每层都是完全填满的,且最后一层的节点都靠左对齐。
堆序性:在最大堆中,父节点的值大于或等于子节点的值;在最小堆中,则相反。
应用
优先队列:用于实现任务调度、图算法中的优先级处理等。
堆排序:利用堆的性质进行高效的排序算法。
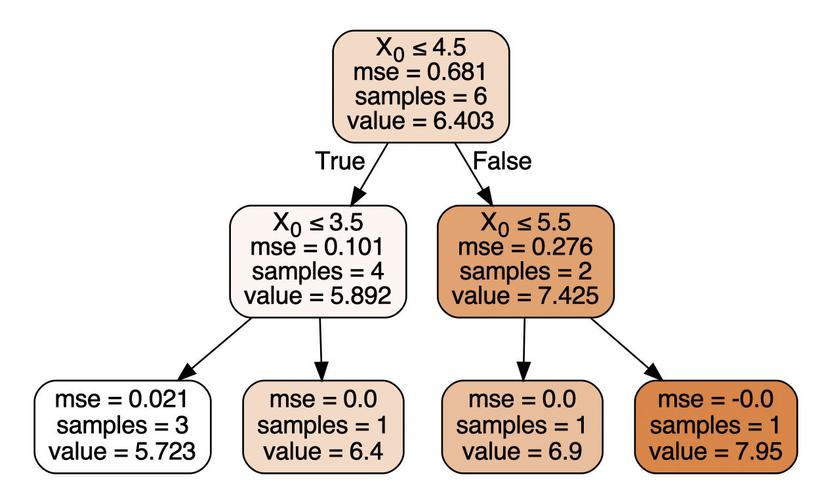
示例
假设我们有一个数组[9, 5, 6, 2, 3],我们可以将其构建为一个最大堆:
9
/
5 6
/
2 3 在这个最大堆中,根节点9是最大的值,满足最大堆的性质。
决策树回归 (Decision Tree Regression)
决策树回归是一种监督学习方法,用来预测连续的目标变量,它通过学习数据特征与目标变量之间的关系来构建模型。
特性
可解释性强:模型的结构直观,易于理解。
非线性拟合:能够捕捉数据中的非线性关系。
容易过拟合:需要剪枝等技术来防止过拟合。
应用
金融分析:预测股票价格、信用评分等。
销售预测:基于历史数据预测未来的销售量。
医疗诊断:根据病人的各项指标预测病情发展。
示例
假设我们要预测房价,并有以下训练数据:
| 面积 | 房间数 | 位置 | 价格 |
| 100 | 2 | 良好 | 200 |
| 150 | 3 | 一般 | 300 |
| 200 | 4 | 良好 | 450 |
通过这些数据,我们可以构建一个决策树模型来预测新房子的价格。
结合点
虽然二叉堆和决策树回归在概念上不直接相关,但在机器学习算法的实现过程中,二叉堆可以作为决策树回归算法中的一个组件,在构建决策树时,可能需要选择一个最佳的划分点,此时可以利用堆结构来高效地存储和检索候选划分点的统计信息。
问题与解答
1、问题: 如何在决策树回归中使用二叉堆?
解答: 在决策树回归中,二叉堆可以用来优化寻找最佳划分属性的过程,当评估每个属性的可能划分点时,可以使用二叉堆来快速访问具有最高信息增益的划分点。
2、问题: 决策树回归模型如何避免过拟合?
解答: 决策树回归模型可以通过剪枝(Pruning)来避免过拟合,这包括预剪枝(提前停止树的增长)和后剪枝(删除已生成树的某些子树),还可以使用正则化技术或者集成方法如随机森林来减少过拟合。
【版权声明】:本站所有内容均来自网络,若无意侵犯到您的权利,请及时与我们联系将尽快删除相关内容!


发表回复