
创建训练作业


在机器学习和数据科学项目中,训练作业是核心环节之一,训练作业指的是使用算法对数据集进行学习,以构建模型的过程,下面将详细介绍如何创建一个训练作业,包括准备数据、选择模型、训练模型以及评估模型性能等步骤。
1. 数据准备
数据准备是训练作业的第一步,它直接影响到模型的质量和泛化能力。
数据采集:根据项目需求,收集相关的数据,可能来源于数据库、文件、网络爬虫等。
数据清洗:处理缺失值、异常值、重复记录等问题,保证数据的质量。
特征工程:提取有用的特征,可能包括数值型、类别型、文本型等,并进行适当的转换和编码。
数据分割:将数据分为训练集、验证集和测试集,通常比例为70%/15%/15%。
2. 模型选择
根据问题类型(分类、回归、聚类等)选择合适的模型。
预选模型:根据经验或文献调研,选择几个潜在的模型,如决策树、随机森林、神经网络等。
基线模型:建立一个简单模型作为基线,比如逻辑回归或线性回归,以便与后续复杂模型进行比较。
3. 模型训练
使用训练集数据来训练模型,调整参数以优化模型性能。
超参数调优:通过网格搜索、随机搜索等方法寻找最优的超参数组合。
交叉验证:使用k折交叉验证等技术避免模型过拟合。
模型训练:在训练集上训练模型,并使用验证集进行模型选择和调参。
4. 模型评估
评估模型在未知数据上的表现,确保模型具有良好的泛化能力。
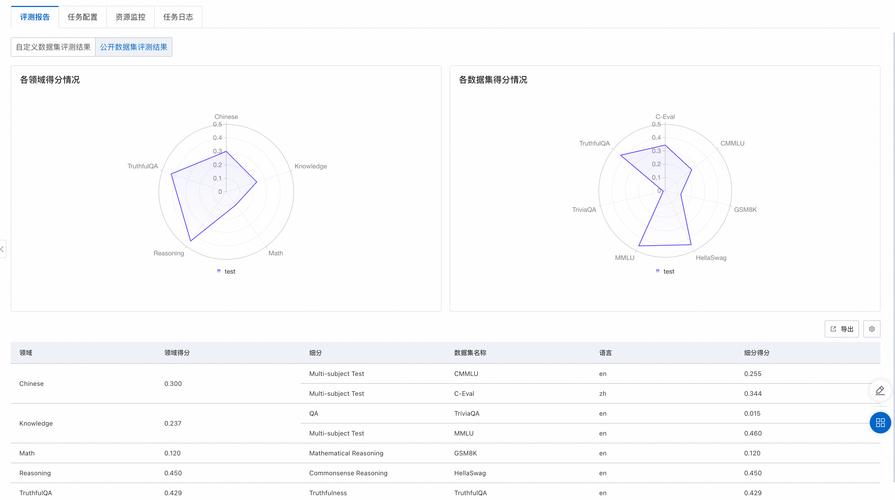
性能指标:根据问题类型选择合适的性能度量指标,如准确率、精确率、召回率、F1分数、均方误差等。
模型测试:在独立的测试集上测试模型性能,确保评估结果的可靠性。
错误分析:分析模型预测错误的样本,找出可能的原因,如数据泄露、模型偏差等。
5. 模型部署
将训练好的模型部署到生产环境中,以供实际应用。
模型保存:保存训练好的模型,可以是模型结构、权重等。
服务接口:搭建API接口,使得模型能够接收请求并返回预测结果。
监控维护:监控模型在生产环境中的表现,定期更新和维护模型。
相关表格
| 阶段 | 关键任务 | 工具/技术 |
| 数据准备 | 数据采集、清洗、特征工程 | 数据库查询、Pandas、NumPy |
| 模型选择 | 预选模型、基线模型 | Scikitlearn、TensorFlow |
| 模型训练 | 超参数调优、交叉验证 | GridSearchCV、K折交叉验证 |
| 模型评估 | 性能指标计算、错误分析 | Scikitlearn评估模块、混淆矩阵 |
| 模型部署 | 模型保存、服务接口、监控维护 | Pickle/Joblib、Flask/Django、Prometheus |
相关问题与解答
Q1: 如何确定模型是否过拟合?
A1: 模型过拟合的迹象包括在训练集上表现很好,但在验证集或测试集上表现不佳,可以通过以下方法进一步确认:
学习曲线分析:如果训练误差和验证误差之间的差距随训练样本数量增加而增大,则可能存在过拟合。
交叉验证:使用k折交叉验证来检查模型在不同子集上的性能是否一致。
复杂度正则化:引入正则化项(如L1、L2正则化)来减少模型复杂度。
Q2: 如何处理不平衡数据集?
A2: 不平衡数据集是指在分类问题中某些类别的样本数量远多于其他类别,处理方法包括:
重采样:对少数类进行过采样或对多数类进行欠采样,以平衡类别分布。
改变性能度量:使用如F1分数、AUCROC曲线等不受类别不平衡影响的性能指标。
合成新样本:使用SMOTE等技术生成新的少数类样本。
成本敏感学习:为不同类别的错误分配不同的惩罚成本,使模型更加关注少数类。
【版权声明】:本站所有内容均来自网络,若无意侵犯到您的权利,请及时与我们联系将尽快删除相关内容!


发表回复