
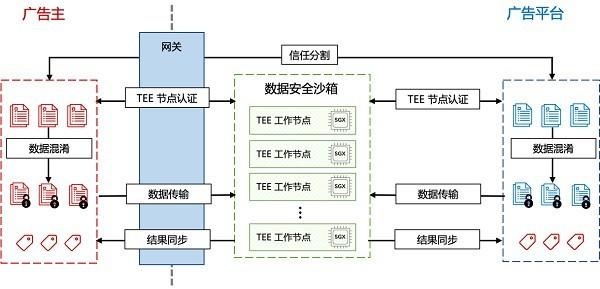
大数据沙盒(Big Data Sandbox)是一种用于处理、分析和挖掘大量数据的实验环境,在沙盒中,用户可以自由地尝试不同的数据处理和分析方法,而不必担心对生产环境造成影响,以下是大数据沙盒的操作流程:

1、确定目标和需求
在开始使用大数据沙盒之前,首先要明确项目的目标和需求,这包括了解需要处理的数据类型、数据量、预期的分析结果等。
2、准备数据
根据项目需求,从各种数据源收集数据,如数据库、日志文件、API等,对收集到的数据进行清洗、转换和整合,以便后续处理和分析。
3、选择技术栈
根据项目需求和团队技能,选择合适的大数据处理和分析技术,常见的技术包括Hadoop、Spark、Hive、Pig等。
4、搭建大数据沙盒环境
根据所选的技术栈,搭建大数据沙盒环境,这可能包括安装和配置相关的软件、设置网络连接、分配计算和存储资源等。
5、导入数据
将准备好的数据导入到大数据沙盒环境中,根据所选的技术栈,可能需要使用特定的工具或命令来完成数据导入。
6、数据处理和分析
在大数据沙盒环境中,使用所选的技术栈对数据进行处理和分析,这可能包括数据清洗、转换、聚合、统计、建模等操作。
7、验证结果
对处理和分析后的结果进行验证,确保其满足项目需求,这可能包括对比预期结果、检查数据质量、评估模型性能等。
8、优化和调整
根据验证结果,对数据处理和分析过程进行优化和调整,这可能包括修改算法参数、调整数据分区、优化资源分配等。
9、部署到生产环境
在沙盒环境中完成数据处理和分析后,将结果部署到生产环境,这可能包括导出数据、配置生产环境、监控性能等。
10、持续改进
在生产环境运行过程中,根据实际需求和反馈,持续改进数据处理和分析方法,这可能包括添加新数据源、优化算法、调整资源分配等。
大数据沙盒的操作流程包括确定目标和需求、准备数据、选择技术栈、搭建环境、导入数据、处理和分析数据、验证结果、优化和调整、部署到生产环境以及持续改进,在整个过程中,需要不断调整和优化,以满足项目需求和提高数据处理和分析效果。
【版权声明】:本站所有内容均来自网络,若无意侵犯到您的权利,请及时与我们联系将尽快删除相关内容!

发表回复