
大数据与数据挖掘

定义和重要性
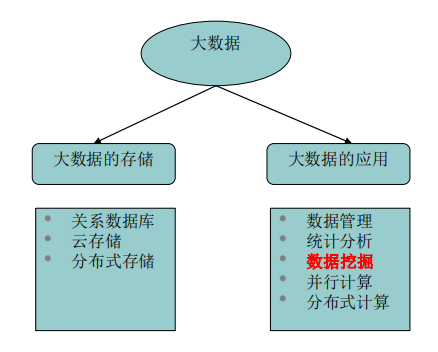
大数据指的是传统数据处理应用软件无法处理的大规模、高增长率和多样化的信息资产集合,它的特点通常被概括为“五V”:大量(Volume)、速度(Velocity)、多样性(Variety)、真实性(Veracity)和价值(Value)。
数据挖掘是从大量的数据中通过算法寻找隐藏的模式或建立模型的过程,目的是发现数据中的有用信息,并利用这些信息做出预测或决策。
大数据技术
分布式计算框架
Hadoop: 基于MapReduce编程模型,能够处理PB级别的数据。
Spark: 提供了比Hadoop更快的处理速度,支持批处理和流处理。
数据库系统
NoSQL数据库: 如MongoDB, Cassandra, 适用于非结构化数据的存储。
NewSQL数据库: 如Google Spanner, CockroachDB, 提供SQL兼容和扩展性。
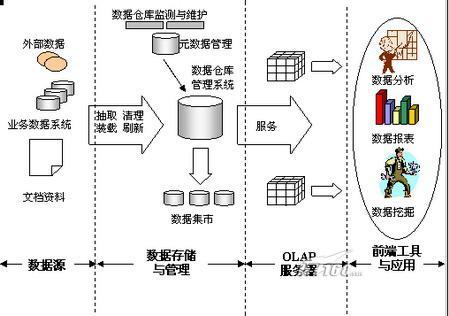
数据湖
允许存储所有类型的原始数据,包括结构化和非结构化数据,便于后续分析。
数据挖掘过程
1、问题定义: 确定挖掘的目的和目标。
2、数据准备: 包括数据清洗、选择、转换等。
3、数据挖掘: 使用各种算法进行模式发现。
4、评估和解释: 对挖掘结果进行评估,解释其意义。
5、部署: 将挖掘结果应用到实际业务中。
数据挖掘技术
分类: 如决策树、随机森林、支持向量机等。
聚类: 如Kmeans、层次聚类、DBSCAN等。
关联规则学习: 用于发现项之间的有趣关系。
序列挖掘: 发现序列数据中的模式。
异常检测: 识别不符合预期模式的数据点。
大数据应用场景
商业智能: 通过分析消费者行为来优化产品和服务。
金融风险管理: 使用大数据工具预测风险和欺诈行为。
健康医疗: 利用患者数据进行疾病预测和治疗优化。
社交媒体分析: 理解用户趋势,改善用户体验。
物联网(IoT): 分析来自传感器的海量数据以监控和维护系统。
大容量数据库
数据库类型
关系型数据库(RDBMS): 如MySQL, PostgreSQL, Oracle, 适合事务性操作。
列式数据库: 如Cassandra, HBase, 适合快速读写和数据分析。
文档数据库: 如MongoDB, 灵活的文档格式存储。
键值存储: 如Redis, DynamoDB, 快速的键值查询。
数据库设计原则
规范化: 减少数据冗余,提高数据完整性。
索引优化: 加快查询速度,降低存储开销。
分区和分片: 提高可扩展性和容错能力。
复制和备份: 确保数据的安全性和可用性。
高性能数据库策略
缓存策略: 使用内存缓存减少磁盘I/O。
负载均衡: 分散请求压力,提高系统吞吐量。
并发控制: 确保多用户环境下的数据一致性。
查询优化: 优化查询计划,减少执行时间。
数据库安全
认证与授权: 确保只有授权用户可以访问数据。
加密: 保护数据在传输和静态状态下的安全。
审计与监控: 跟踪数据访问记录,防止非法操作。
数据完整性检查: 防止数据损坏和篡改。
相关问题与解答
Q1: 大数据与数据挖掘之间有什么关系?
A1: 大数据提供了数据挖掘所需的庞大数据集,而数据挖掘则是从这些大数据集中发现有价值信息的技术手段,两者相互依赖,大数据为数据挖掘提供原料,数据挖掘则为理解和利用大数据提供方法。
Q2: 如何选择合适的数据库系统?
A2: 选择合适的数据库系统需要考虑数据的类型(结构化或非结构化)、访问模式(读密集或写密集)、性能要求、预算限制以及是否需要水平扩展等因素,对于需要高速读写和弹性扩展的场景,可能更适合选择NoSQL数据库;而对于需要复杂查询和事务支持的应用,则可能需要传统的关系型数据库。
【版权声明】:本站所有内容均来自网络,若无意侵犯到您的权利,请及时与我们联系将尽快删除相关内容!

发表回复