
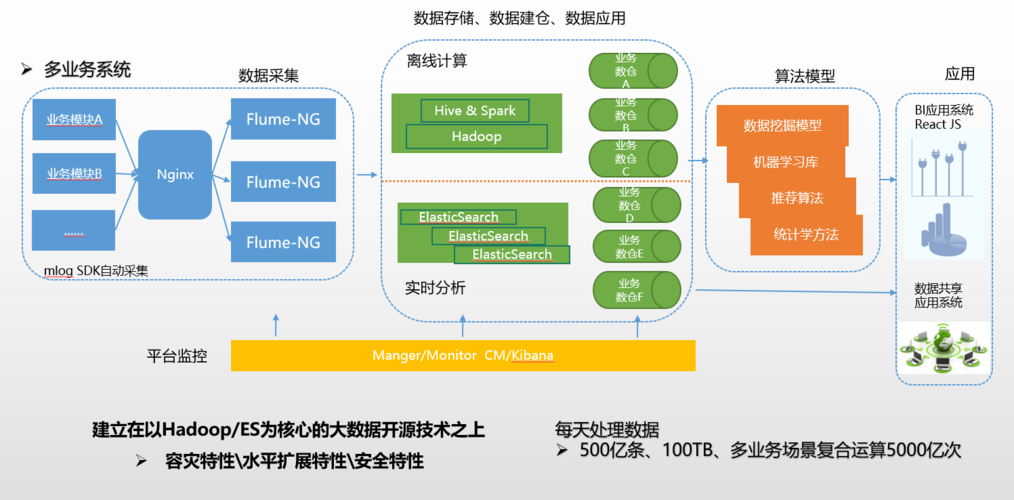

随着互联网和信息技术的飞速发展,数据量呈现出爆炸式增长,大数据存储作为处理这些海量数据的基础,其重要性不言而喻,大数据存储技术需要解决数据的高效存取、管理、分析和保护等问题。
分布式文件系统
hadoop distributed file system (hdfs):一个高度可靠和可扩展的分布式文件系统,设计用来存储大量的数据,并提供高吞吐量的数据访问。
数据库技术
nosql数据库:非关系型数据库,如mongodb、cassandra、hbase等,它们能够水平扩展以应对大量数据。
newsql数据库:提供sql接口的关系型数据库,同时具备nosql的扩展能力,例如google spanner、cockroachdb。
数据仓库
数据湖:一种存储结构化和非结构化数据的集中式存储库,例如aws s3、azure data lake storage。

数据仓库:专门用于存储经过整理的业务数据,支持复杂的查询操作,如amazon redshift、snowflake。
内存计算框架
apache spark:提供高速的数据处理能力,尤其适合迭代算法和快速查询。
大数据存储解决方案案例
案例1:社交媒体数据分析
1、问题描述:社交媒体平台每天产生数以亿计的数据点,包括文本、图片、视频等。
2、解决方案:使用hadoop生态系统(hdfs、hive、spark)进行数据存储和分析。
3、实施步骤:
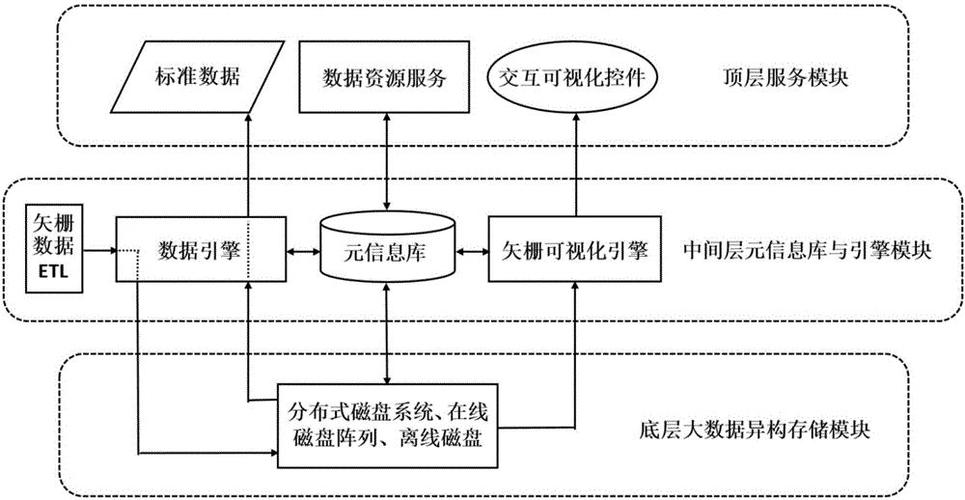
部署hdfs集群来存储原始数据。
使用hive进行数据仓库建设,便于执行sql查询。
利用spark进行实时数据处理和机器学习任务。
案例2:金融交易数据处理
1、问题描述:金融机构需要处理和分析大量的交易数据,以识别市场趋势和欺诈行为。
2、解决方案:采用高性能的数据仓库和实时数据处理平台。
3、实施步骤:
部署高性能数据仓库如redshift。
结合使用kafka进行数据流处理。
应用machine learning模型进行异常检测。
相关问题与解答
q1: 如何选择合适的大数据存储解决方案?
a1: 选择大数据存储解决方案时,需要考虑以下因素:
数据特性:考虑数据的类型(结构化/非结构化)、规模和增长速度。
应用场景:根据是批处理、实时处理还是交互式查询来确定技术选型。
成本预算:权衡存储和计算资源的成本效益。
技术成熟度与社区支持:选择有良好社区支持且文档丰富的技术。
兼容性与集成性:考虑解决方案是否易于与现有系统集成。
q2: 大数据存储面临的挑战有哪些?
a2: 大数据存储主要面临的挑战包括:
数据安全性:保护数据不被未授权访问或丢失。
数据治理:确保数据质量、一致性和合规性。
性能与扩展性:满足不断增长的数据量和访问需求,保持高性能。
成本控制:存储和管理大规模数据的成本往往很高。
技术选型与维护:面对不断演进的技术栈,做出合适的技术选择并持续维护。
【版权声明】:本站所有内容均来自网络,若无意侵犯到您的权利,请及时与我们联系将尽快删除相关内容!


发表回复