
背景
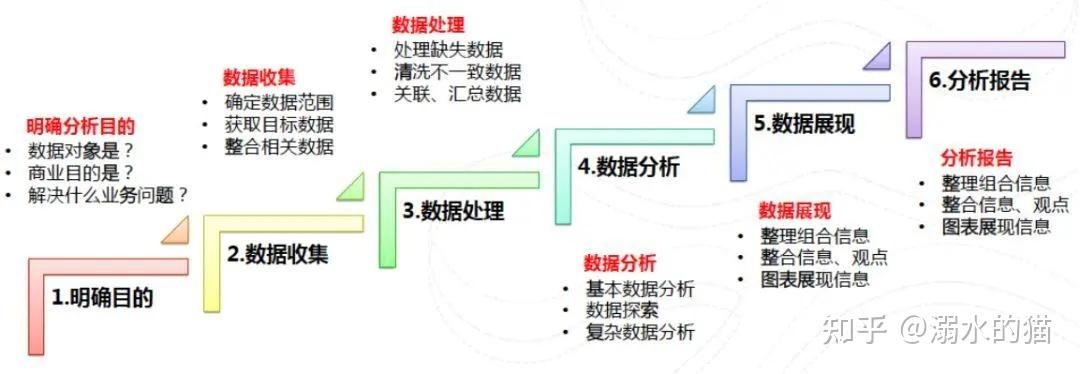

在大数据应用中,中间表通常用于存储临时结果或作为不同处理步骤之间的桥梁,随着数据量的增加和查询复杂度的提升,传统的行式存储方式可能无法满足性能要求,因此需要调整存储策略以优化查询效率和存储成本。
问题描述
某公司的数据仓库在处理用户行为分析时,发现中间表的查询响应时间过长,影响了整个数据处理流程的效率,该中间表包含用户ID、事件类型、时间戳等字段,主要用于连接用户基本信息和行为日志。
解决方案
1. 存储格式调整
原存储方式
使用行式存储,每个字段连续存储。
适用于点查询和少量更新操作。
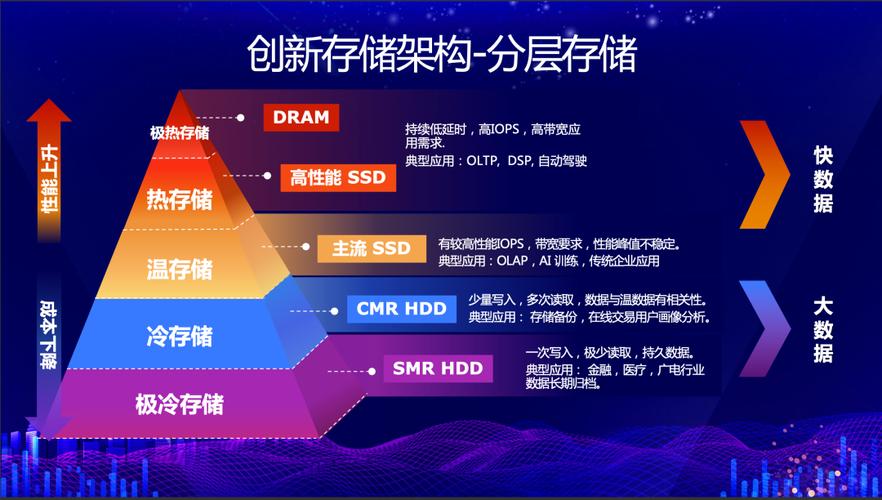
调整后存储方式
采用列式存储,每个字段独立存储。
适用于大范围扫描和聚合操作。
2. 索引优化
原索引设置
仅对用户ID设置B树索引。
调整后索引设置
对用户ID、事件类型和时间戳设置位图索引。
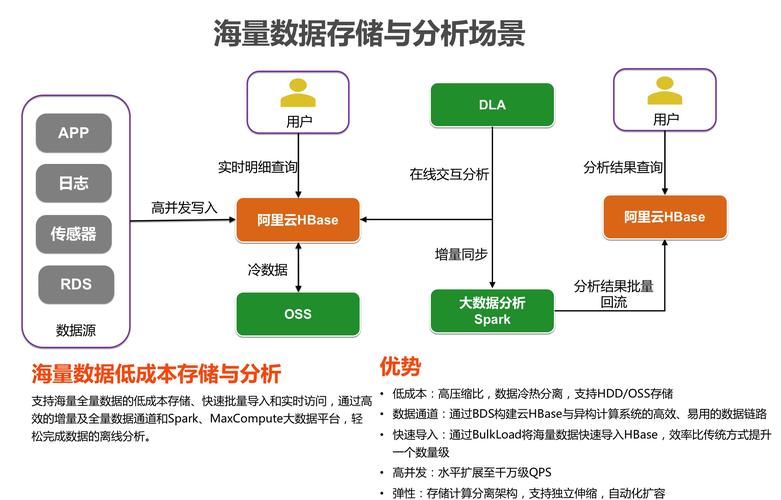
加速多条件查询和范围查询。
3. 分区策略
原分区策略
未进行分区。
调整后分区策略
根据时间戳按月分区,提高数据管理效率和查询速度。
4. 压缩技术
原压缩技术
未使用压缩技术。
调整后压缩技术
使用列式存储自带的高效压缩算法,如字典编码和行程编码。
实施效果
通过上述调整,中间表的查询性能得到显著提升,同时存储空间也得到有效节省,具体表现在:
查询速度提升了约50%。
存储空间节省了约30%。
相关问题与解答
Q1: 为什么列式存储比行式存储更适合大范围扫描和聚合操作?
A1: 列式存储将同一列的数据存储在一起,这使得在进行大范围扫描和聚合操作时,只需读取相关的列,而不是整行数据,这样可以减少I/O操作,提高查询效率,列式存储通常会配合高效的压缩技术,进一步减少数据读取量。
Q2: 分区策略如何影响查询性能?
A2: 分区策略可以将大表分割成多个小表,每个小表包含一部分数据,这样在执行查询时,如果可以通过分区键过滤掉不相关的分区,就只需要扫描相关的分区,从而大大减少查询范围和提高查询速度,分区还可以并行处理查询,进一步提升性能。
【版权声明】:本站所有内容均来自网络,若无意侵犯到您的权利,请及时与我们联系将尽快删除相关内容!


发表回复