
通过使用Sqoop工具,用户可以实现MySQL数据库与Hadoop之间的数据相互转移,这在大数据环境下尤为重要,下面将深入探讨如何通过Sqoop将MySQL数据库中的数据导入HDFS,并对接外部存储系统:

1、准备工作
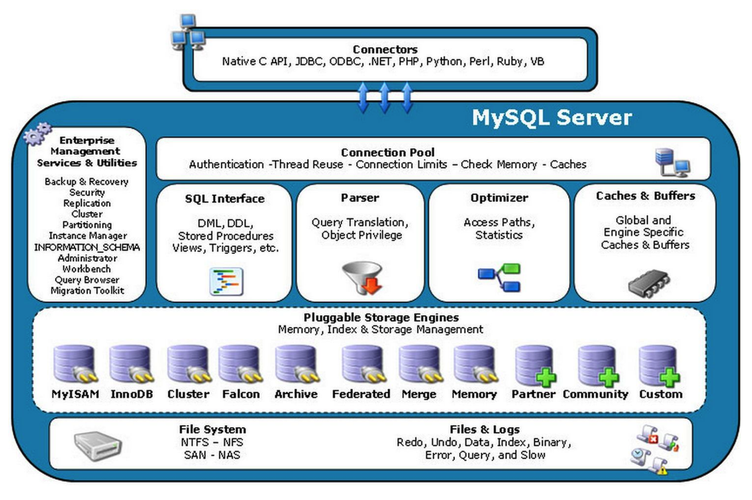
环境设置:确保你的Hadoop和Sqoop环境已经正确安装和配置,这包括Java环境、Hadoop集群以及Sqoop工具的部署。
驱动安装:为了连接MySQL数据库,需要下载并安装MySQL的JDBC驱动,可以从MySQL官方网站下载对应版本的JDBC驱动,然后将其放置在Sqoop的lib目录下。
2、使用Sqoop导入数据
基本命令:使用Sqoop的import命令,结合connect参数来指定MySQL数据库的连接信息,包括服务器地址、端口号、数据库名。
认证信息:使用username和password参数来提供连接到数据库所需的用户名和密码。
指定表和目标:使用table参数来指定要导入数据的表名,而targetdir参数则是用来指明HDFS中的目标路径。
并行化处理:可以通过m参数来指定使用多少个map任务进行并行数据导入,这可以大大提升数据导入的效率。
3、导出数据到MySQL
执行Sqoop导出:当需要从HDFS导出数据至MySQL时,可以使用Sqoop的export命令,同样需要通过connect参数指定数据库连接信息。
指定HDFS源目录:使用exportdir参数指定HDFS上的源目录,即要从哪个HDFS路径导出数据。
验证数据:数据导出后,建议验证数据库中的数据是否与HDFS中的源数据一致,以确保数据的准确性。
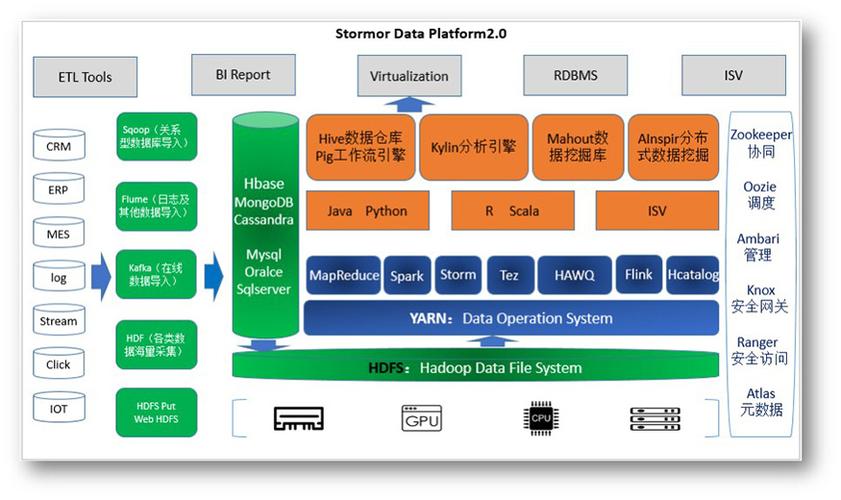
4、对接外部存储系统
扩展Sqoop功能:虽然Sqoop主要设计用于与关系型数据库和Hadoop之间转移数据,但可以通过编写自定义的插件或者使用其他工具与之配合,实现与更多类型的外部存储系统的对接。
利用中间件:可以考虑使用如Flume等中间件,将Sqoop导出的数据进一步转移到其他类型的存储系统中。
理解Sqoop的工作细节及其在数据处理生态中的位置非常重要,对于大规模数据集,考虑数据压缩和安全性也是至关重要的,保持对最新技术的关注,比如使用更先进的数据湖架构(如Apache Hudi或Iceberg)来管理数据,可能会为你的数据处理流程带来优化,这些技术的引入,不仅能提高数据处理效率,还能增强数据的可管理性和分析能力。
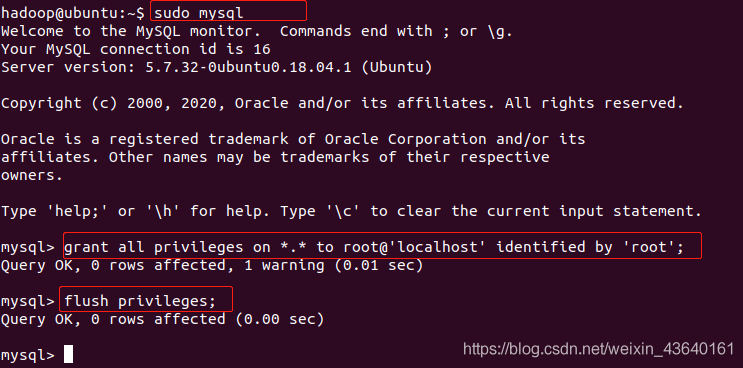
通过Sqoop将MySQL数据库中的数据导入HDFS,涉及到了环境准备、数据导入及导出的具体操作,以及与其他存储系统的集成策略,掌握这些步骤和技巧,可以帮助你在大数据项目中有效地管理数据流,从而支持数据分析和决策制定过程。
【版权声明】:本站所有内容均来自网络,若无意侵犯到您的权利,请及时与我们联系将尽快删除相关内容!


发表回复