
非结构化数据中心涉及的非结构化抽取,是从多样且无固定格式的数据中提取有价值的信息,涉及到一系列的技术和方法。

非结构化数据普遍存在于人们的日常生活中,例如文本文档、电子邮件、图像和视频等,这类数据通常没有固定的组织结构,使得其处理和分析比起传统的结构化数据要更为复杂,为了有效地利用这些数据,需要借助一些专门的技术进行信息的抽取,具体分析如下:
1、非结构化数据的定义与类型
数据定义: 非结构化数据是指任何不具有预定义结构或组织的数据,不同于数据库中的结构化数据,这些数据通常是无组织的,如文本、图像或视频信息。
数据类型: 非结构化数据可以分为人类生成的数据,如电子邮件、社交媒体帖子等,以及机器生成的数据,如传感器数据、日志文件等。
2、非结构化数据的管理与存储
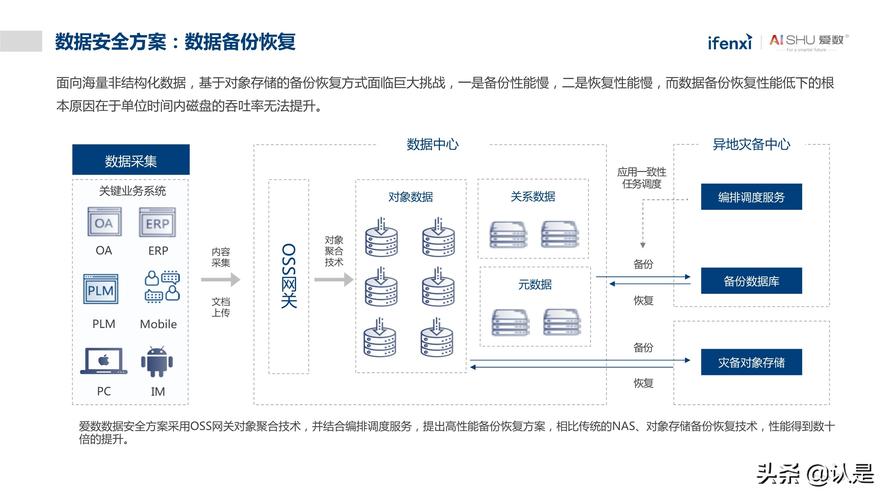
数据收集: 通过各种API及数据摄取工具,如Apache NiFi或Logstash,从不同的来源收集数据,以便进行进一步的处理和分析。
数据存储: 采用可扩展的存储解决方案来处理大量的非结构化数据,这些解决方案能够适应数据的快速增长和多样性。
3、非结构化数据的转换与处理
实体抽取: 从非结构化文本数据中识别和抽取关键的信息元素,如人名、地点或组织名,这可以通过序列标注模型如HMM、CRF以及更现代的LSTM+CRF等方法实现。
实体识别与链接: 识别出文本中的实体后,还需要将这些实体与知识库中的相应实体进行链接,这一过程涉及到实体消岐和知识的关联。
4、关系抽取
定义与方法: 关系抽取指从文本中抽取出两个或多个实体之间的语义关系,如“父子关系”、“雇佣关系”等,这可以通过基于模板的Pattern、依存句法分析或机器学习等方法进行。
5、事件抽取
概念: 事件抽取指从文本中识别出特定的事件以及相关的参数,例如时间、地点、参与者等,这是信息抽取中的一个高级任务,涉及到复杂的自然语言处理技术。
6、共指消解
: 共指消解是指在文本中识别出指向同一实体的多个表述,并将它们关联起来,这对于理解文本的意义和上下文非常重要。
7、非结构化数据分析的技术与工具
技术概述: 分析非结构化数据可以使用自然语言处理(NLP)、计算机视觉、音频处理等技术,结合深度学习等机器学习方法来自动化地提取和分析数据。
具体应用: 使用NLP技术可以从文本数据中提取关键信息,而计算机视觉技术则用于从图像数据中提取信息。
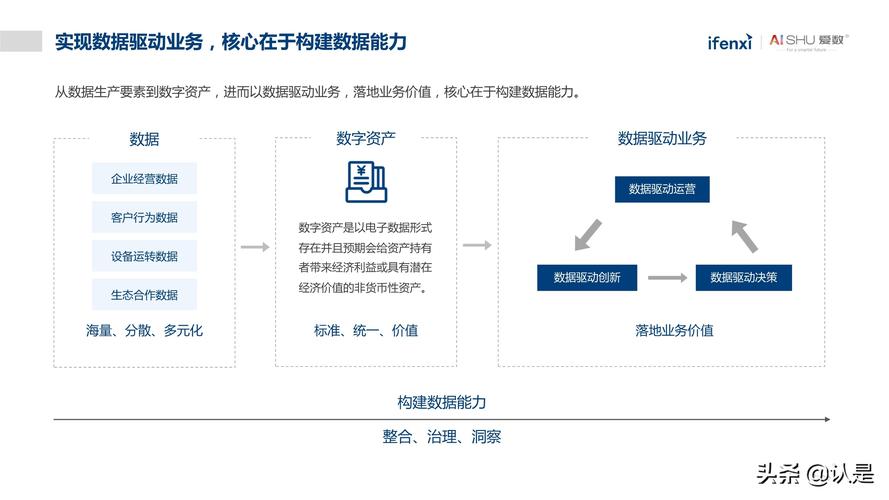
非结构化数据中心的非结构化抽取是一项复杂但至关重要的任务,它涉及多种技术的综合应用,从数据的初步收集到高级的信息抽取和知识生成,随着技术的进步,这些方法将不断优化,为人们提供更深入的洞见和更精确的分析结果。
【版权声明】:本站所有内容均来自网络,若无意侵犯到您的权利,请及时与我们联系将尽快删除相关内容!

发表回复