
3.4使用示例 在方法上添加注解即可, @Cache(key = "#userName", expiryTime = 60)

public User getUserByUserName(String userName) {
return userDao.getUserByUserName(userName);
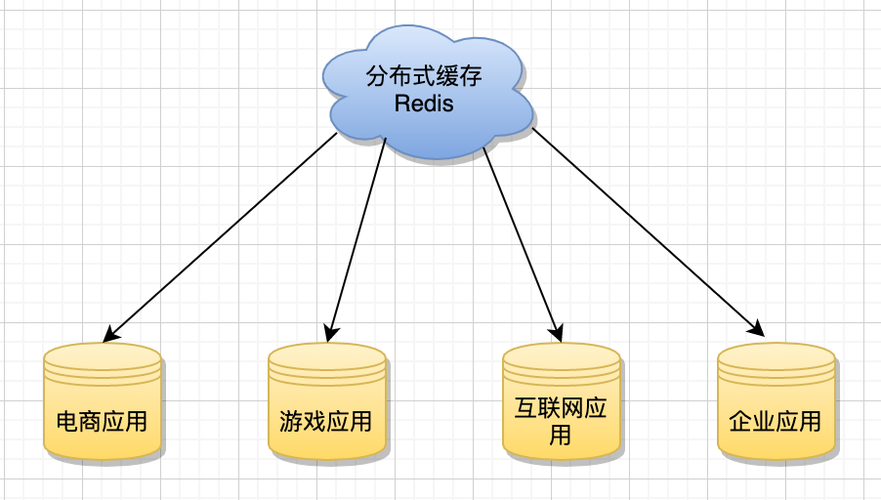
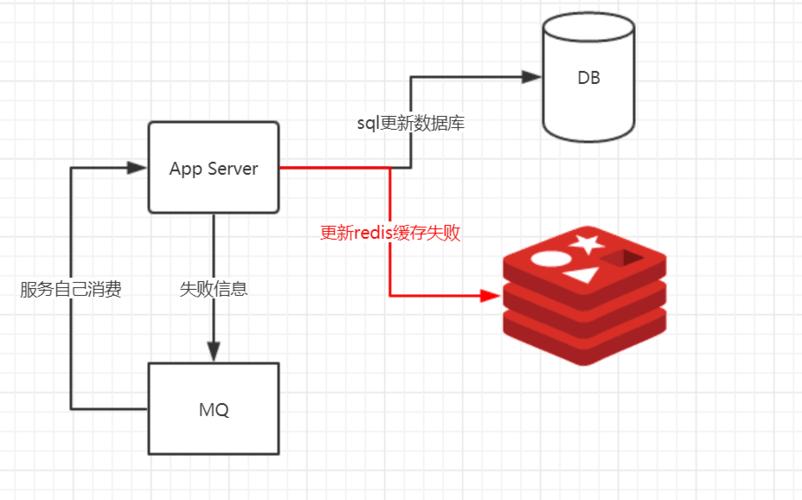
四、数据一致性 缓存中的数据与数据库中的数据不一致的问题,通常有几种解决方式。 4.1缓存更新策略 常见的缓存更新策略有两种: 写时更新(Write Through):当写操作发生时,同时将数据写入到缓存和数据库中,这种方式下,缓存和数据库中的数据保持一致,但是会增加系统的开销。 回写(Write Back):只有在缓存中的数据需要被替换时,才将其写入到数据库中,这种方式可以减少系统开销,但是可能会存在数据不一致的风险。 4.2缓存读写过程 在读取数据时,先从缓存中读取,如果缓存中没有,则从数据库中读取,并将数据写入缓存,在写入数据时,可以先写入数据库,再写入缓存;也可以先写入缓存,再写入数据库,具体的选择取决于业务需求和性能要求。 五、高可用 5.1缓存穿透 缓存穿透是指查询一个不存在的数据,由于缓存没有命中,会去数据库查询,查不到数据则返回空,这样对数据库压力较大,解决方法是在缓存中存储一个空值或者特殊标记,当再次查询时直接返回这个空值或者特殊标记。 5.2缓存击穿 缓存击穿是指当某个热点数据的key过期的瞬间,大量的并发请求涌入数据库,造成数据库瞬时压力剧增,解决方法是使用互斥锁或者分布式锁来保证同一时刻只有一个请求去数据库查询数据并更新缓存。 5.3缓存雪崩 缓存雪崩是指当大量数据的key同时过期,导致大量的请求都去访问数据库,造成数据库压力过大,解决方法是对不同的数据设置不同的过期时间,或者使用互斥锁来防止过多的请求同时访问数据库。 5.4Redis 集群 为了提高缓存系统的可用性和扩展性,可以使用 Redis 集群,通过数据分片技术,将数据分散到多个节点上,即使某个节点宕机,其他节点仍然可以提供服务,集群也可以提供更高的吞吐量和更低的延迟。
【版权声明】:本站所有内容均来自网络,若无意侵犯到您的权利,请及时与我们联系将尽快删除相关内容!

发表回复