
服务器运维方案设计

1. 概述
1.1 目标与范围
本运维方案旨在确保服务器的稳定运行,最大化系统的可用性、可靠性和性能,涵盖的范围包括硬件管理、软件部署、系统监控、安全管理、备份与恢复、故障处理以及文档记录等。
1.2 参考标准
遵循ITIL(信息技术基础设施图书馆)最佳实践、ISO/IEC 27001信息安全管理标准和相关行业规范。
1.3 定义和缩略语
SLA:服务等级协议
RTO:恢复时间目标
RPO:恢复点目标
ITIL:信息技术基础设施图书馆
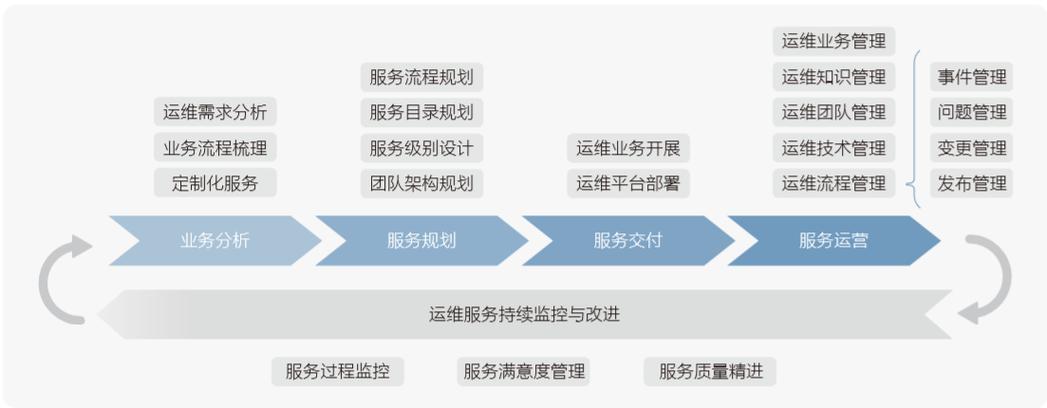
2. 运维团队结构
2.1 角色与职责
运维经理:负责整体运维策略规划与执行监督。
系统管理员:负责日常系统维护、故障排除和性能优化。
网络工程师:负责网络设备的管理和维护。
安全专家:负责安全性评估和应急响应。
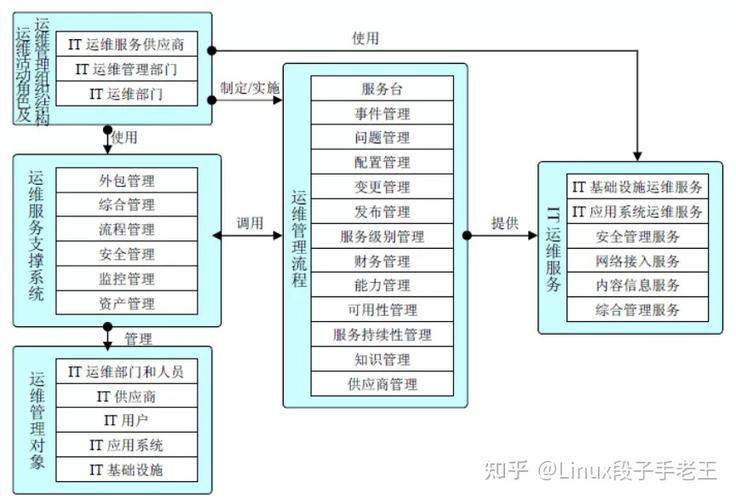
2.2 运维流程
事件管理:快速响应和解决突发事件。
问题管理:识别并解决根本原因,防止问题再次发生。
变更管理:控制和管理对生产环境的变更。
3. 硬件管理
3.1 服务器规格
详细列出服务器的硬件配置,包括CPU、内存、存储空间和网络接口等。
3.2 硬件维护计划
定期进行硬件检查、清洁和更新,确保硬件处于良好状态。
4. 软件部署
4.1 操作系统部署
选择适合的操作系统版本,制定标准化安装流程。
4.2 应用软件部署
根据业务需求,部署必要的应用程序和服务。
4.3 补丁管理
制定补丁测试和部署流程,确保系统安全。
5. 系统监控
5.1 监控工具
选用合适的监控工具,如Zabbix、Nagios或Prometheus。
5.2 性能监控
监控CPU、内存、磁盘使用率和网络流量等关键指标。
5.3 日志管理
集中收集和分析系统日志,用于故障诊断和安全审计。
6. 安全管理
6.1 安全策略
制定严格的安全策略,包括密码管理、访问控制和安全审核等。
6.2 防火墙与入侵检测
配置防火墙规则,部署入侵检测系统(IDS)。
6.3 数据加密
对敏感数据进行加密处理,保护数据安全。
7. 备份与恢复
7.1 备份策略
根据RPO和RTO制定备份计划,选择合适的备份介质和备份周期。
7.2 备份执行
自动化执行定期备份,并验证备份数据的完整性。
7.3 灾难恢复计划
制定详细的灾难恢复流程,确保在紧急情况下能快速恢复服务。
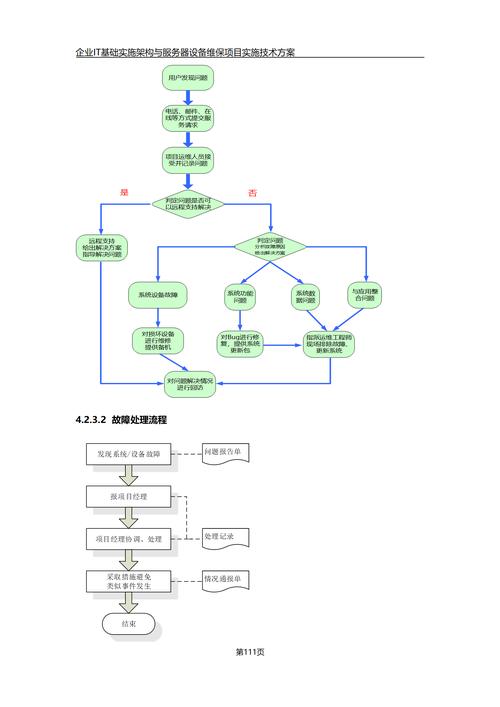
8. 故障处理
8.1 故障响应流程
明确故障报告、分析和解决的流程。
8.2 故障排查指南
编写故障排查手册,指导快速定位和解决问题。
8.3 预防措施
通过持续监控和及时维护减少故障发生概率。
9. 文档与培训
9.1 运维文档
建立完整的运维文档体系,包括操作手册、配置文档和变更记录等。
9.2 培训计划
定期对运维人员进行技术和流程培训,提升团队能力。
10. 性能优化
10.1 优化策略
根据系统监控结果,制定针对性的性能优化方案。
10.2 资源调整
根据业务需求和系统负载,动态调整资源分配。
11. 服务质量管理
11.1 SLA监控
监控服务质量,确保满足SLA要求。
11.2 客户反馈
建立客户反馈机制,及时调整服务策略。
12. 持续改进
12.1 改进机制
建立持续改进机制,定期评审运维流程和效果。
12.2 技术趋势跟进
关注技术发展趋势,适时引入新技术提升运维效率。
【版权声明】:本站所有内容均来自网络,若无意侵犯到您的权利,请及时与我们联系将尽快删除相关内容!


发表回复