
Kafka流式集群和传统集群的差异在于应用场景、吞吐量、扩展性等方面,快速购买Kafka流式集群操作包括选择配置、设置网络、配置安全等步骤。
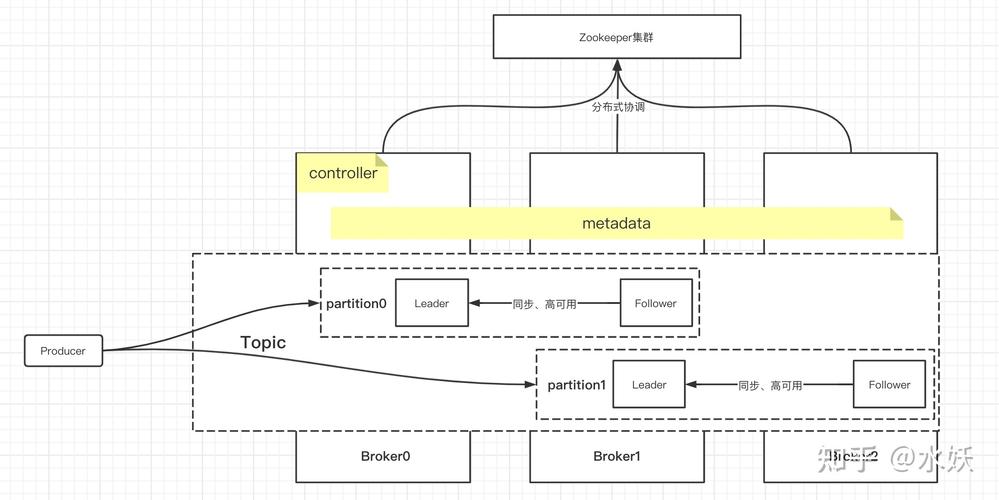

差异分析:
1、应用场景:
Kafka流式集群:专为需要高吞吐量和可扩展性的实时数据处理设计,可用于日志收集、实时监控数据聚合等场景,优势在于支持高峰时段的大量消息处理需求。
传统集群:通常设计为通用目的,可能不具备特定于实时数据处理的优化。
2、吞吐量:
Kafka流式集群:高吞吐量是其显著特点,能够处理海量消息,同时保证较低的延迟。
传统集群:可能在吞吐量和延迟方面不如专门优化过的Kafka流式集群。
3、扩展性:
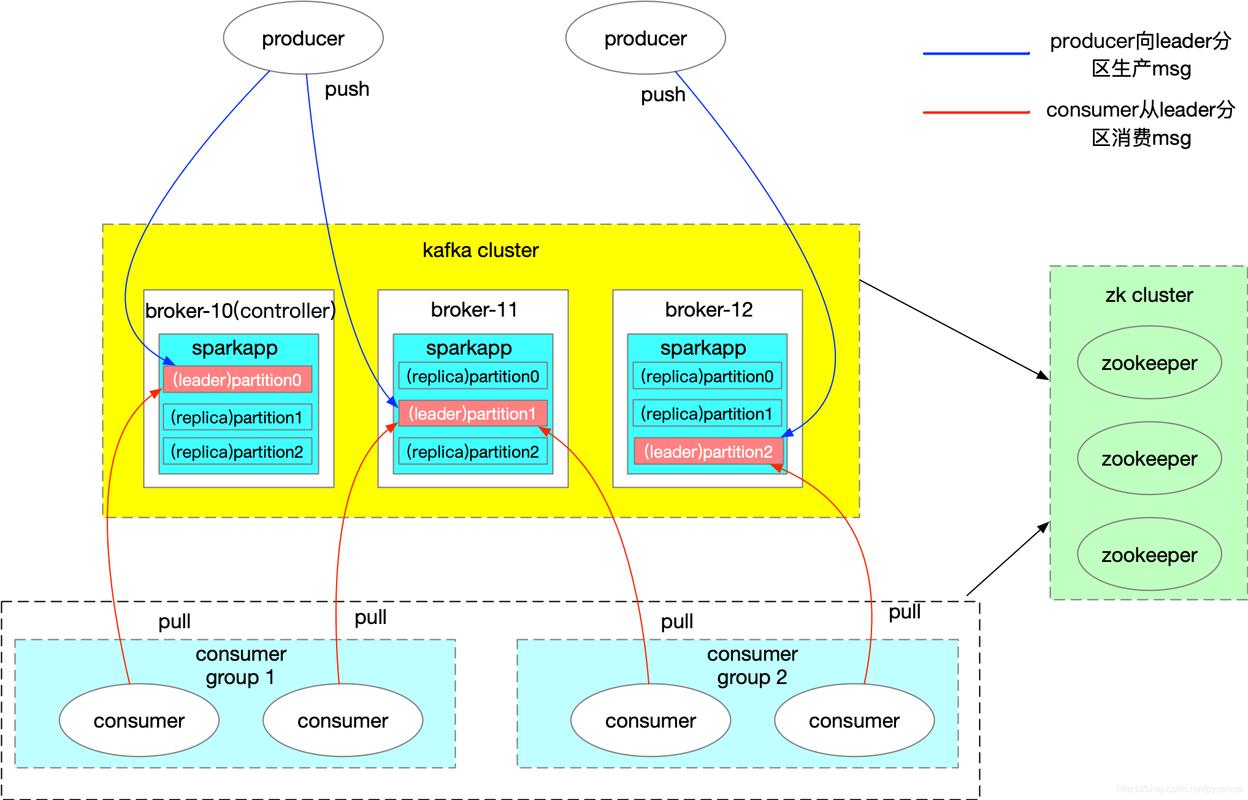
Kafka流式集群:设计为易于水平扩展,以应对不断增长的数据量。
传统集群:扩展能力可能受限于架构和所用技术。
4、容错性:
Kafka流式集群:复制机制支持数据在集群中的备份,提高系统的容错能力。
传统集群:容错性取决于集群的具体配置和软件。
5、持久化:
Kafka流式集群:支持数据持久化,确保消息可以被可靠地存储。
传统集群:数据持久化能力依赖于应用和配置。
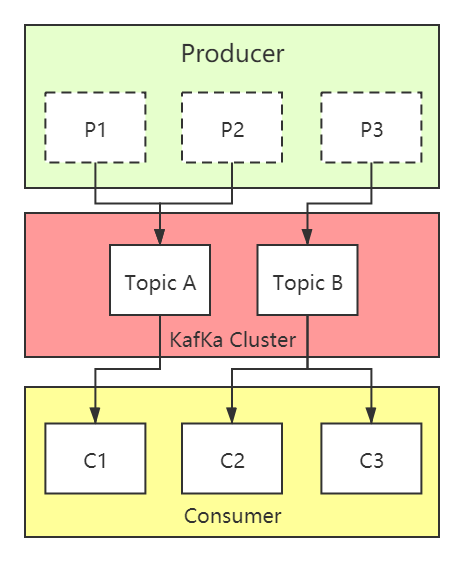
6、实时处理:
Kafka流式集群:针对实时数据处理进行了优化。
传统集群:可能需要额外的工具和配置才能高效处理实时数据。
7、解耦能力:
Kafka流式集群:支持应用和分析系统之间的有效解耦,通过消息队列实现组件间的松耦合。
传统集群:解耦能力取决于架构设计。
8、兼容性:
Kafka流式集群:通常与如Storm、Spark等实时处理引擎配合使用,为实时分析和批量处理提供良好支持。
传统集群:需要根据具体应用选择兼容的技术和框架。
快速购买Kafka流式集群的步骤:
1、选择配置:
进入购买MRS集群页面,选择“快速购买”页签。
根据实际需求配置集群基本信息,如区域、计费模式、集群名称、类型、版本等。
2、设置网络:
选择合适的可用区和企业项目。
配置虚拟私有云(VPC)和子网,如果未创建VPC,需新建。
3、配置安全:
决定是否开启Kerberos认证,一旦购买后,不支持修改此设置。
设置root和admin用户的密码,并确认密码。
4、勾选授权:
阅读并勾选通信安全授权,继续购买流程。
5、提交订单:
确认所有配置无误后,点击“立即购买”。
6、查看状态:
购买后,可以在集群列表中查看集群创建的状态。
7、等待创建完成:
创建过程需要时间,集群将从“启动中”变为“运行中”。
Kafka流式集群在设计上是为了应对高吞吐量和实时数据处理的挑战,而传统集群更适用于通用的计算任务,快速购买Kafka流式集群时,关注集群配置、网络设置、安全保障等关键步骤,可以确保获取到满足业务需求的高效、可靠的实时数据处理能力。
【版权声明】:本站所有内容均来自网络,若无意侵犯到您的权利,请及时与我们联系将尽快删除相关内容!


发表回复