
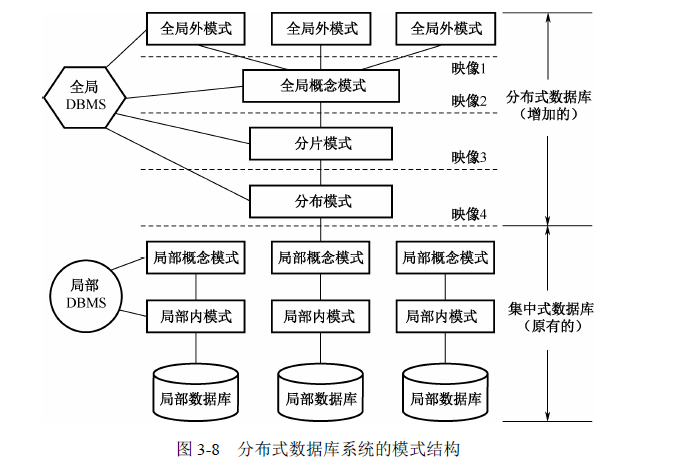
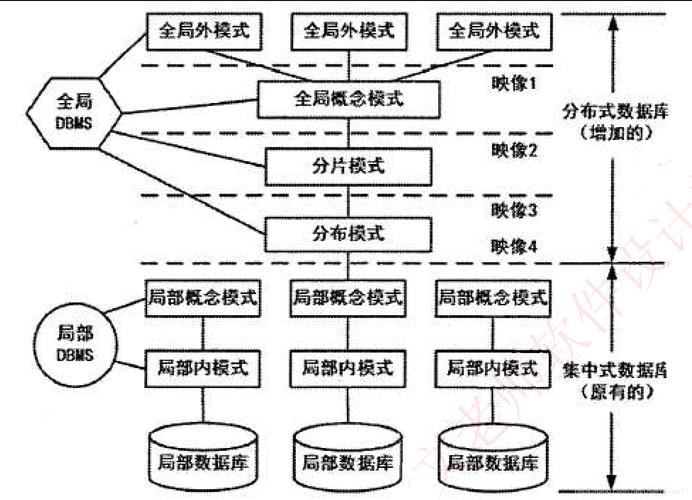
分布式数据库同步是通过将数据在不同节点间复制和同步来保持数据一致性的过程,在分布式系统中,由于数据被存储在多个节点上,为了确保数据的完整性和一致性,分布式数据库同步显得尤为重要,下面将深入探讨分布式数据库同步的不同方面:

1、同步动机与背景
数据一致性:分布式数据库同步的核心目的是确保各个节点上的数据保持一致,这对于支持数据的读写、负载均衡及容灾等方面都是极其重要的。
系统可靠性:通过同步,即使部分节点发生故障,系统依然能够保证数据的可靠性和可用性。
2、同步解决方案
数据复制同步:通过主从复制、多主复制或链式复制等方式,将数据从一个节点复制到其他节点实现同步。
事件日志同步:通过记录数据的变更操作为事件日志,并将日志传播到其他节点重放来实现同步。
分区同步:每个节点只负责同步其所属分区的数据,提高同步效率和并发性。
3、同步工具与实践
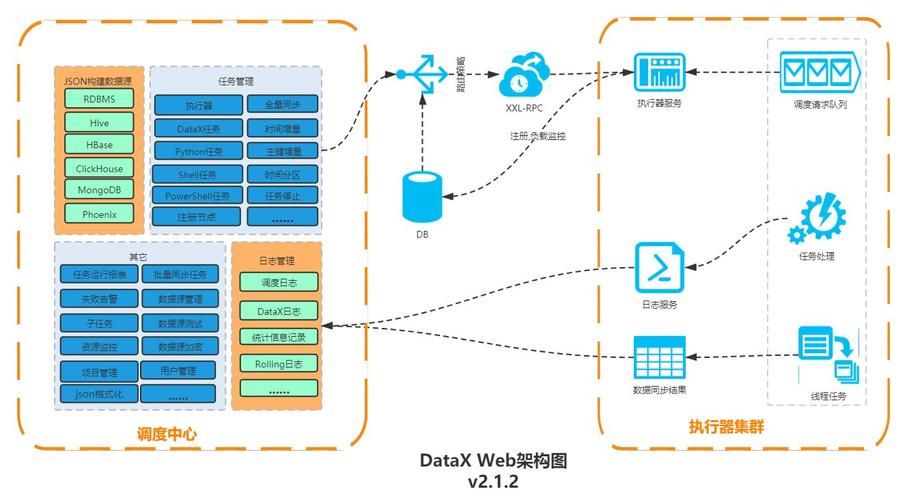
自研工具:如百度开发者中心介绍的redisGunYu,它通过伪装成redis slave同步数据,并支持分片不对称、拓扑变化等功能。
开源方案:如redisshake、DTS(alibaba)、xpipe等,但它们可能无法满足所有需求,如支持分片不对称、高可用等。
4、同步过程与细节
输入端:伪装成redis slave,从源redis节点同步数据。
通道端:即本地缓存,管理RDB和AOF数据。
输出端:读取本地缓存数据写入目标端redis主库。
5、同步策略与机制
断点续传:支持在同步过程中的失败恢复。
数据一致性:保证最终或弱一致性。
高可用:同步工具本身设计为高可用,避免单点故障。
6、同步优化与运维
数据过滤:可以针对某些正则key、db、命令等进行过滤。
监控:提供丰富的监控指标,如时间与空间维度的复制延迟指标。
API:通过http API进行运维操作,如强制全量复制、同步状态、暂停同步等。
分布式数据库同步是确保分布式系统数据一致性、可靠性和系统伸缩性的关键,选择合适的同步方案、工具和最佳实践,可以有效解决同步延迟、并发冲突和数据一致性等挑战,通过监控和调优数据同步性能,及时发现和解决同步问题,是确保系统稳定性和可靠性的重要手段。
【版权声明】:本站所有内容均来自网络,若无意侵犯到您的权利,请及时与我们联系将尽快删除相关内容!


发表回复