
MapReduce是一种专门用于大规模数据集并行处理的编程模型,特别适合处理大容量数据库,在面对海量数据时,传统的数据处理方法往往显得力不从心,不仅效率低下,而且难以应对数据的分布性和异构性,MapReduce正是为解决此类问题而设计的高效框架,它将复杂的分布式计算任务简化为Map和Reduce两个阶段,极大地提高了大数据处理的效率和可行性。
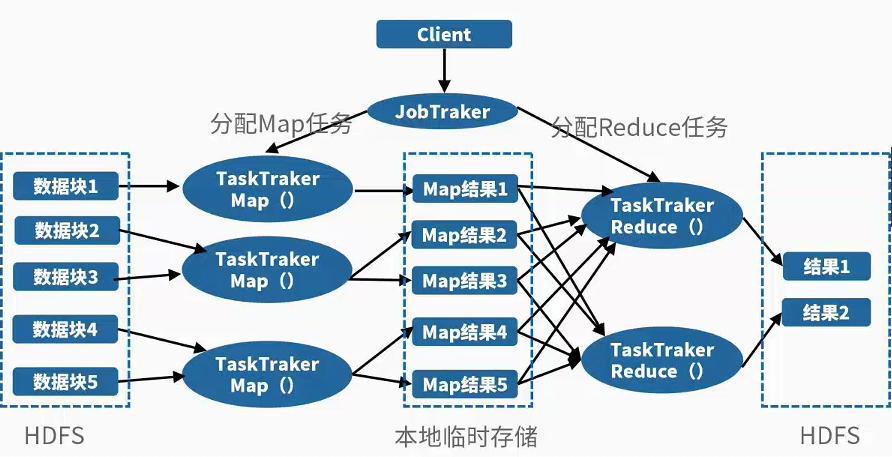

MapReduce的核心思想是将大规模数据处理任务分解为许多小任务,这些小任务可以并行处理,最后再将结果汇总起来,Map阶段负责对输入数据进行初步的处理,生成一系列键值对;而Reduce阶段则对这些键值对按照键进行归类和处理,最终得到所需的结果,这种模式不仅简化了并行计算的复杂性,还通过数据分区和局部处理减少了网络传输量,提升了系统的整体性能。
在架构上,MapReduce通常采用主从结构,包括一个Master节点和多个Slave节点,Master节点负责作业的调度和状态管理,而Slave节点则执行实际的Map和Reduce任务,客户端提交作业后,Master节点(JobTracker)负责协调整个作业的运行,包括任务分配、监控和失败恢复等;Slave节点(TaskTracker)则根据分配到的任务执行Map或Reduce操作,并定期向Master报告进度,这种设计使得MapReduce具有很好的扩展性和容错性,能够适应大规模集群环境。
MapReduce作为处理大容量数据库的重要工具,不仅简化了大规模并行计算的复杂性,还通过其高效的数据分片、任务调度和容错机制,大大提升了大数据处理的性能和可靠性,尽管面临新的挑战和竞争技术,MapReduce的基本思想和优化经验仍然值得学习和借鉴。
【版权声明】:本站所有内容均来自网络,若无意侵犯到您的权利,请及时与我们联系将尽快删除相关内容!

发表回复