
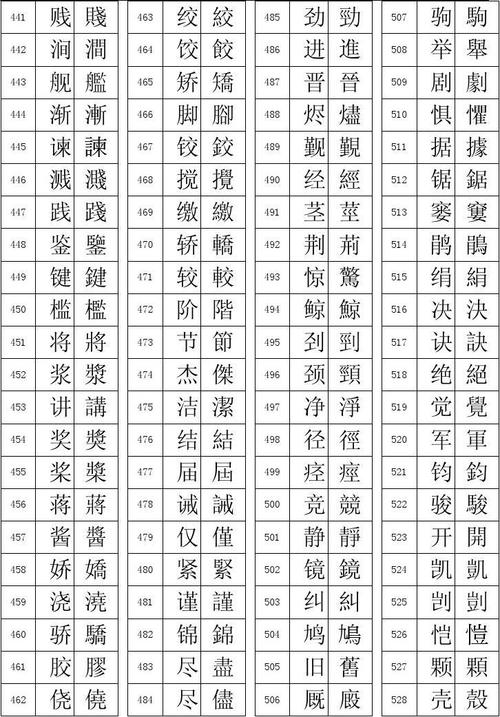
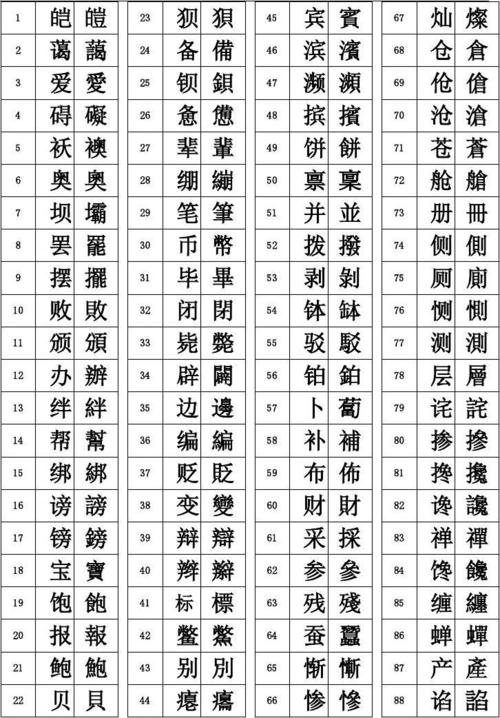
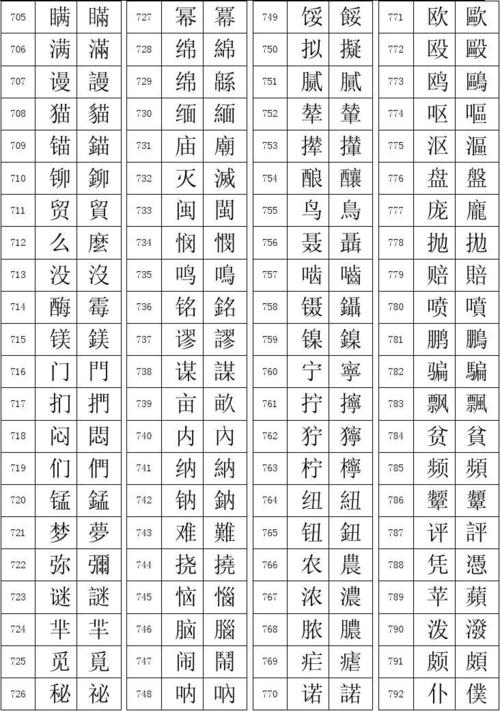
繁体文字識別_文字識別,,{写51字
繁体文字识别是指通过计算机技术对繁体中文字符进行自动识别和处理的过程,繁体中文字符主要使用于台湾、香港、澳门等地区,与简体中文字符相比,笔画更为复杂,文字识别技术可以帮助人们快速、准确地将纸质文档、图片等介质中的繁体中文字符转换为电子文本,提高工作效率。

(图片来源网络,侵删)
以下是一些关于繁体文字识别的关键技术和方法:
1、图像预处理:在进行文字识别之前,需要对输入的图像进行预处理,包括去噪、二值化、归一化等操作,以提高识别准确率。
2、特征提取:从预处理后的图像中提取有助于区分不同字符的特征,如边缘、角点、纹理等,常用的特征提取方法有HOG(Histogram of Oriented Gradients)、SIFT(ScaleInvariant Feature Transform)等。
3、分类器设计:根据提取的特征,设计分类器对字符进行识别,常用的分类器有支持向量机(SVM)、神经网络(Neural Network)、随机森林(Random Forest)等。
4、后处理:对识别结果进行校正和优化,如利用词典匹配、语言模型等方法,提高识别准确率。
5、训练数据集:为了训练一个高性能的繁体文字识别系统,需要大量的标注数据,这些数据可以来自于公开数据集,也可以是自行收集并标注的数据。
6、评估指标:评估繁体文字识别系统的性能,常用的指标有准确率(Accuracy)、召回率(Recall)、F1分数(F1 Score)等。
繁体文字识别是一个涉及图像处理、特征提取、分类器设计等多个领域的复杂问题,随着深度学习技术的发展,基于神经网络的文字识别方法逐渐取代了传统的机器学习方法,取得了更好的识别效果。
(图片来源网络,侵删)
(图片来源网络,侵删)
【版权声明】:本站所有内容均来自网络,若无意侵犯到您的权利,请及时与我们联系将尽快删除相关内容!


发表回复