
python,from pyspark.sql import SparkSession,,# 创建SparkSession,spark = SparkSession.builder , .appName("StructuredStreamingExample") , .getOrCreate(),,# 从数据源读取数据并进行处理,df = spark , .readStream , .format("csv") , .option("header", "true") , .schema(schema) , .csv("/path/to/data") , .writeStream , .outputMode("append") , .format("console") , .start(),,# 等待流处理结束,df.awaitTermination(),“Spark Structured Streaming 是 Apache Spark 的一个扩展,它提供了对实时数据流处理的支持,在 Spark Structured Streaming 中,你可以使用熟悉的批处理概念和 API 来处理持续的数据流。
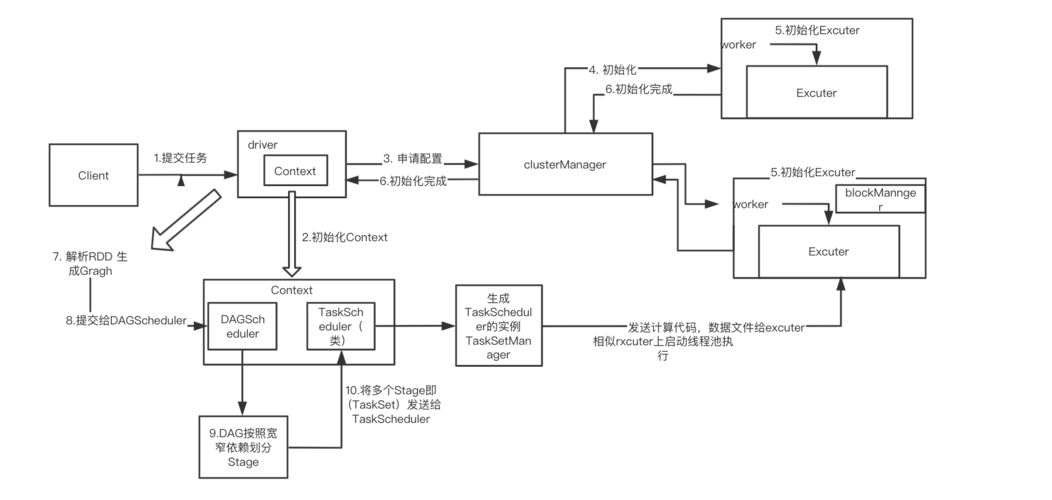

以下是一个使用 Python 编写的简单 Spark Structured Streaming 样例程序:
from pyspark.sql import SparkSession
from pyspark.sql.functions import explode
创建 SparkSession
spark = SparkSession.builder
.appName("Explode Example")
.getOrCreate()
读取 JSON 文件作为数据流
streamingInputDF = spark
.readStream
.schema(json_schema)
.json("/path/to/input/json/files")
将每个 JSON 对象中的 "values" 数组字段展开
explodedDF = streamingInputDF
.select(explode(streamingInputDF["values"]).alias("value"))
.select(col("value.*"))
查询并输出结果
query = explodedDF
.writeStream
.outputMode("append")
.format("console")
.start()
query.awaitTermination() 在上面的代码中:
1、我们导入必要的模块,并创建一个 SparkSession。
2、我们从指定的路径读取 JSON 文件,并将其视为数据流。
3、我们使用explode 函数将每个 JSON 对象中的 "values" 数组字段展开,这个函数会将数组字段展开为多行,每行包含数组中的一个元素。
4、我们启动查询并将结果输出到控制台。
这个示例程序的主要目的是展示如何使用 Spark Structured Streaming 进行实时数据处理,在这个例子中,我们从一个包含 JSON 对象的文件夹读取数据,然后将每个对象中的 "values" 数组字段展开,并将结果输出到控制台。
注意:在实际使用中,你需要替换"/path/to/input/json/files" 为你的实际输入路径,同时定义你的json_schema。
相关的问题:
1、Q: 如果输入的 JSON 文件中没有 "values" 字段,上面的程序会怎么样?
A: 如果输入的 JSON 文件中没有 "values" 字段,那么explode 函数会返回一个空的结果,因为没有任何元素可以展开,这不会引发错误,但可能会导致结果不符合预期,为了避免这种情况,你可以在应用explode 之前检查 "values" 字段是否存在。
2、Q: 如果我想将结果保存到文件而不是控制台,我应该怎么做?
A: 如果你想将结果保存到文件,你可以修改输出模式和格式,如果你想将结果保存为文本文件,你可以将.format("console") 改为.format("text"),并提供一个输出路径,如.option("path", "/path/to/output/files"),这样,结果将被保存到你指定的路径。

【版权声明】:本站所有内容均来自网络,若无意侵犯到您的权利,请及时与我们联系将尽快删除相关内容!


发表回复