
非结构化数据通常指那些不符合传统数据库格式的多样化数据,如文本、图片、音频和视频等,这些数据因其多样性和复杂性,使得从中提取有用信息变得尤为重要且挑战重重,有效的非结构化抽取技术能够将这些数据转化为有价值的信息,支持决策制定和业务优化。
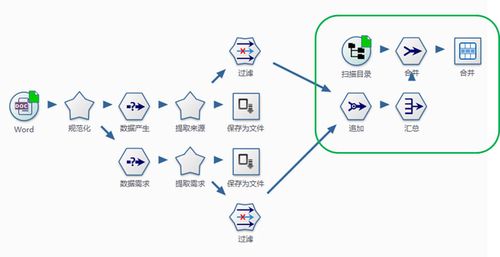

从文本中进行知识抽取是处理非结构化数据的一大关键任务,它包括自动化地从文本中发现、提取相关信息,并将非结构化数据转化为结构化数据,这一过程涉及到命名实体识别(NER)、术语抽取、关系抽取以及事件抽取等子任务,在处理新闻文章或社交媒体帖子时,通过NER可以识别出人名、地名、组织名等信息,而关系抽取则能确定这些实体之间的各种关系,如地理位置属于哪个国家,或者两个人之间的关系等,这种抽取工作对于构建知识图谱、支持搜索引擎和提升推荐系统的准确性都有着重要作用。
为了提高非结构化数据抽取的准确性和效率,现代技术已经采用了多种先进的机器学习和深度学习模型,使用条件随机场(CRF)和长短期记忆网络(LSTM)结合的模型来处理序列数据,有效地进行实体识别,弱监督学习也被广泛应用于关系抽取中,斯坦福大学的DeepDive系统就是利用这种方法通过远程监督从文本中抽取结构化关系数据。
随着技术的不断进步,未来非结构化数据的抽取将会更加依赖于深度学习技术和多模态交互技术的发展,这意味着文本、图像、视频等多种类型的数据将共同用于训练模型,以提高抽取的全面性和准确性,优化现有的数据处理流程,解决大数据量处理和模型泛化能力的问题也将是未来发展的重点。
在许多实际应用中,非结构化数据的抽取不仅需要应对技术挑战,还要面对数据质量不一、来源多样等问题,在医疗和法律行业中,需要从病历记录和法律文档中提取关键信息以支持专业人士的决策,在这些领域,除了技术解决方案外,合适的数据预处理和后处理也同样重要,以确保最终结果的准确性和可用性。
非结构化数据的抽取是一个涉及多种技术和方法的复杂过程,随着人工智能和机器学习技术的不断发展,这一领域将持续提供新的解决方案和改进方法,以应对不断增长的数据处理需求。
【版权声明】:本站所有内容均来自网络,若无意侵犯到您的权利,请及时与我们联系将尽快删除相关内容!


发表回复