
在大数据时代,大模型微调作为机器学习领域的一个关键环节,对数据有着一定的要求,将详细探讨这些要求:

1、数据质量要求
数据清洗:在微调大模型之前,需要对数据进行清洗,以确保数据的准确性和一致性,这包括去除错误的数据点、处理缺失值和异常值等。
特征工程:特征工程是数据预处理的重要组成部分,它涉及到选择、变换和构建对模型性能有积极作用的特征,恰当的特征工程可以显著提升模型的泛化能力和准确率。
标注准确性:对于有监督学习任务,数据标注的准确性至关重要,高质量的标注数据能够提供清晰的学习信号,从而训练出性能更好的模型。
2、数据规模要求
数据量:虽然有些研究指出,即使使用少量的数据(例如1.9M tokens)也可以实现对特定任务模型的有效微调,但数据的量依然对模型性能有一定的影响,特定任务如提取、分类、封闭式QA和归纳摘要任务,模型性能随着数据量的增加而提高。
数据多样性:数据多样性对于模型的泛化能力至关重要,丰富多样的数据集可以帮助模型学习到不同场景下的知识和规律,从而提高其适应性和鲁棒性。
3、数据格式要求
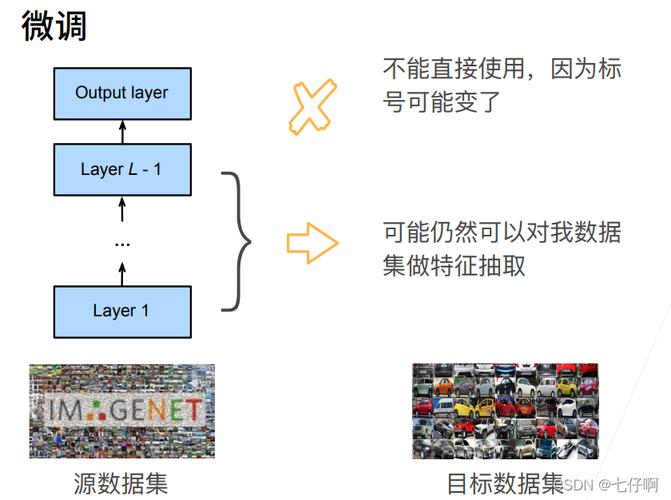
指令格式:指令微调的数据需要采用一定的格式,这些格式决定了模型学习的方式和效果,alpaca和sharegpt提供了两种不同的数据格式,分别适用于不同的应用场景和模型架构。
结构化数据:对于某些特定的NLP任务,结构化的数据输入(如对话历史、系统提示词等)对于模型学习如何根据上下文生成响应是有帮助的。
4、要求
相关性:微调数据应与目标任务高度相关,以便模型能够学习到最直接和最具体的知识。
代表性:数据应能充分代表实际应用场景中的分布,避免偏差和过度拟合特定类型的数据。
5、数据质与量的关系
质优于量:近年来的一些研究表明,在数据质量上的投入比简单增加数据量带来的好处可能更大。《LIMA:Less Is More for Alignment》一文的实验显示,在优化数据质量时,收益会增加。
质与量的平衡:虽然数据质量对模型的性能有重要影响,但在实际应用中也需要根据具体任务和资源情况,合理平衡数据质量和数据量的关系。

6、数据来源
公开数据集:研究者和开发者通常可以利用公开可用的数据集进行模型的微调。
自定义数据集:对于特定的业务场景或独特的研究领域,可能需要自己构建数据集,这通常需要更多的时间和资源,但可以为模型带来特定的优势。
7、数据预处理的重要性
去噪:去除噪声数据可以防止模型学习到错误的模式,从而提高最终的性能。
增强:数据增强技术如随机翻转、旋转、裁剪等,可以在一定程度上提升模型的泛化能力,尤其是在图像处理领域。
在大模型的应用中,数据的质量、规模、格式、内容以及它们之间的关系对于最终的模型性能有着重要的影响,开发者在进行大模型微调时,需要特别关注这些方面,以确保模型能够达到最优的性能,随着技术的不断发展,如何更高效地利用数据,减少数据需求,同时提升模型性能,将是未来研究的一大趋势。
大模型微调对数据的要求体现在多个层面,包括但不限于数据的质量和数量,通过精心的数据处理和明智的数据策略,可以有效提升模型的性能,减少不必要的资源消耗,并加速模型的迭代和优化过程。
【版权声明】:本站所有内容均来自网络,若无意侵犯到您的权利,请及时与我们联系将尽快删除相关内容!


发表回复