
elasticsearch(简称es)是一个分布式、restful风格的搜索和分析引擎,通常用于处理大量数据的实时搜索和日志数据分析,作为一个基于lucene构建的搜索引擎,它扩展了全文搜索的能力,并提供了高速、可扩展和高可靠的数据存储机制。

elasticsearch的核心概念:
文档(document):在es中,文档是索引信息的基本单位,通常可以将其视为数据库中的一行记录。
索引(index):索引是文档的容器,类似于关系数据库中的数据库或表。
分片(shard):为了提高系统的伸缩性和容错能力,索引被分割成多个分片,每个分片可以独立地存储在不同的节点上。
副本(replica):副本是分片的复制,可以提高数据的可用性和查询性能。
大容量数据库特性:
水平扩展性(horizontal scalability):通过增加更多的节点来扩展系统容量,而不是升级单个节点的硬件配置。
分布式处理(distributed processing):查询请求可以在多个节点上并行执行,提高了查询效率。
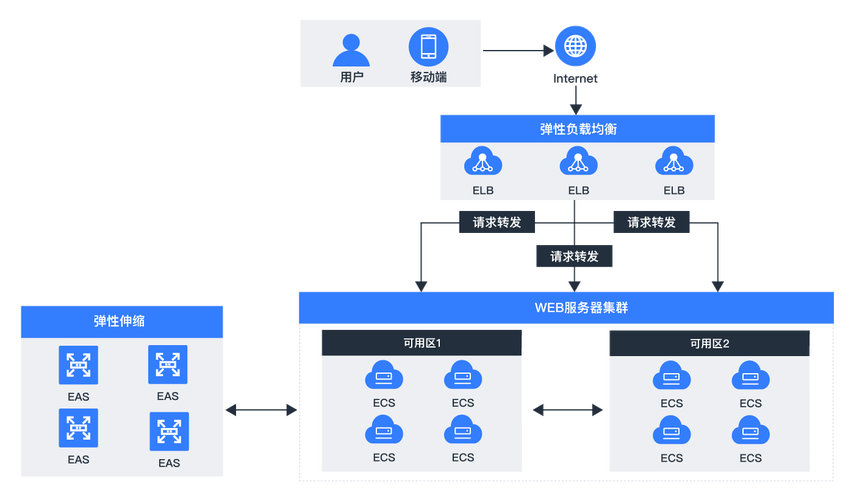
近实时搜索(near realtime search):es能够快速地将新数据索引到现有索引中,使得搜索结果几乎实时更新。
高可靠性(high availability):通过副本机制,即使部分节点失效,系统仍然可以提供服务。
elasticsearch的数据模型:
es的数据模型非常灵活,支持多种数据类型,包括文本、数字、日期、布尔值等,并且支持嵌套的对象和数组,这为复杂的数据结构提供了便利。
使用场景:
日志管理(log management):由于其强大的搜索和分析功能,es常用于集中管理和分析日志数据。
实时分析(realtime analytics):es能够处理大量数据并提供实时的分析结果,适用于需要快速反馈的场景。
全文检索(fulltext search):es优化了文本搜索的性能,适用于网站内容、论坛帖子等的全文检索。
安全分析(security analytics):es可以用于收集和分析安全事件,帮助检测潜在的威胁。
架构与部署:
es集群由多个节点组成,每个节点可以有不同的角色,如主节点(负责集群元数据的管理)、数据节点(存储数据和执行数据相关的操作)、协调节点(接收客户端请求并分发到适当的节点)。
性能优化:
缓存:利用es的请求缓存和分片缓存来提升查询性能。
索引优化:合理设计索引结构,避免过于宽泛的索引,减少不必要的字段映射。
并发控制:调整并发设置以避免资源竞争导致的性能问题。
相关技术:
kibana:与es配合使用的开源数据可视化工具,用于展示和交互式分析es中的数据。
logstash:一个服务器端的数据处理管道,用于同时从多个来源采集数据,转换数据,然后将数据发送到es。
表格归纳:
| 特性 | 说明 |
| 分布式 | 支持跨多台机器的水平扩展 |
| 弹性 | 可以根据需要动态调整资源分配 |
| 实时性 | 提供近乎实时的数据索引和搜索 |
| 高可靠 | 通过数据副本保证服务的高可用性 |
| 易扩展 | 可以通过添加节点轻松扩展系统容量 |
问题与解答:
q1: elasticsearch如何保证数据的一致性?
a1: elasticsearch通过所谓的“主从同步”机制来保证数据的一致性,写入操作首先发生在主分片上,然后同步到其副本分片,读操作可以在主分片或任何副本分片上进行,es还使用了乐观并发控制来处理并发写操作,确保数据的一致性。
q2: 如何监控elasticsearch集群的健康状态和性能?
a2: 可以使用elasticsearch自带的监控工具如cat api和_cluster api来获取集群的状态和统计信息,第三方工具如elastic hq, grafana, kibana等也可以与elasticsearch集成,提供更全面的监控和可视化选项。
【版权声明】:本站所有内容均来自网络,若无意侵犯到您的权利,请及时与我们联系将尽快删除相关内容!

发表回复