
模型开发简介

模型开发是数据科学、机器学习和人工智能领域的核心环节,它涉及到构建能够从数据中学习和做出预测或决策的数学模型,这些模型可以用于各种应用,如自然语言处理、图像识别、推荐系统等,本文将简要介绍模型开发的流程、工具和技术,以及面临的挑战。
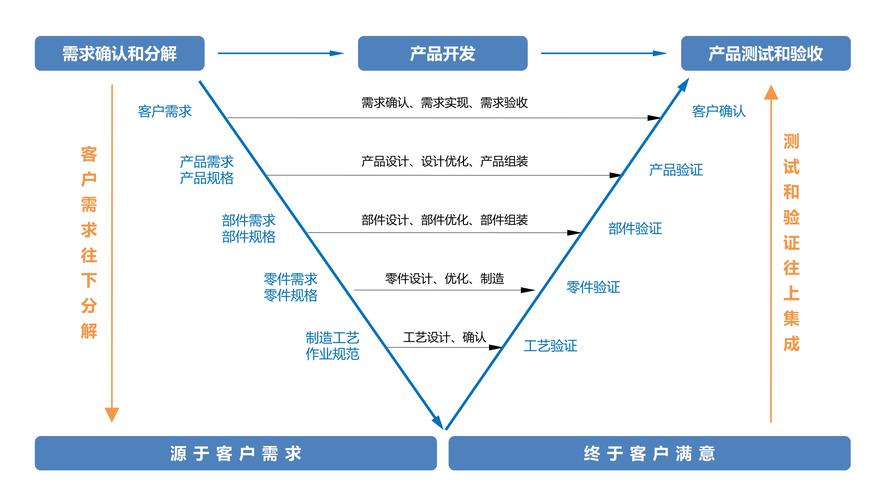
模型开发流程
模型开发通常遵循以下步骤:
1、问题定义: 明确模型需要解决的具体问题,例如分类、回归或聚类任务。
2、数据收集: 获取足够的数据来训练模型,这可能包括数据采集、清洗和预处理。
3、特征工程: 选择或构建对模型性能影响显著的特征。
4、模型选择: 确定使用哪种类型的模型,如线性回归、决策树或神经网络。
5、模型训练: 使用训练数据集来调整模型参数。
6、模型评估: 通过验证集或交叉验证等方法来评估模型性能。
7、模型优化: 根据评估结果调整模型结构或参数,进行特征选择或正则化以提升性能。

8、模型部署: 将训练好的模型部署到生产环境,开始实际预测工作。
9、模型监控与维护: 监控模型在生产环境中的表现,定期更新以应对概念漂移。
常用工具与技术
模型开发过程中常用的工具和技术包括:
编程语言: Python和R是最常用的编程语言,因为它们有大量的库支持数据分析和机器学习。
机器学习框架: 如TensorFlow, PyTorch, scikitlearn等提供了广泛的算法支持。
数据处理工具: 如Pandas, NumPy用于数据清洗和预处理。
可视化工具: 如Matplotlib, Seaborn用于数据的可视化分析。
云计算平台: 如AWS, Google Cloud, Azure提供了强大的计算资源和机器学习服务。
面临的挑战
数据质量和量的问题: 高质量和大量的数据是模型开发的关键,但往往难以获得。
过拟合与欠拟合: 找到合适的模型复杂度以避免过拟合(模型在训练数据上表现好,但在新数据上表现差)和欠拟合(模型过于简单,无法捕捉数据的内在规律)。
模型解释性: 尤其是深度学习模型,其“黑盒”特性使得模型的决策过程难以解释。
相关问题与解答
Q1: 如何选择合适的机器学习模型?
A1: 选择机器学习模型时,应考虑以下几个因素:问题的类别(分类、回归等)、数据的特性(特征数量、是否有噪声等)、模型的可解释性需求、计算资源和时间限制,初步可以从简单的模型(如线性回归、逻辑回归)开始,逐步尝试更复杂的模型(如随机森林、神经网络),并通过交叉验证等方法评估不同模型的性能。
Q2: 如何处理不平衡数据集?
A2: 不平衡数据集指的是数据集中各类别的样本数量差异很大,处理不平衡数据集的方法有多种,包括但不限于:重采样(过采样少数类或欠采样多数类)、使用合成数据生成技术(如SMOTE)、选择合适的评估指标(如F1分数、AUCROC曲线),以及调整分类阈值,采用特定的算法(如代价敏感学习)也可以有效处理不平衡数据问题。
【版权声明】:本站所有内容均来自网络,若无意侵犯到您的权利,请及时与我们联系将尽快删除相关内容!

发表回复