
MySQL 是一个广泛使用的开源关系型数据库管理系统(RDBMS),它并不是一个多维数据库,通过一些技巧和扩展,MySQL 可以支持多维数据分析的某些方面,让我们探讨一下多维视图和多维分支在 MySQL 中的实现方式。
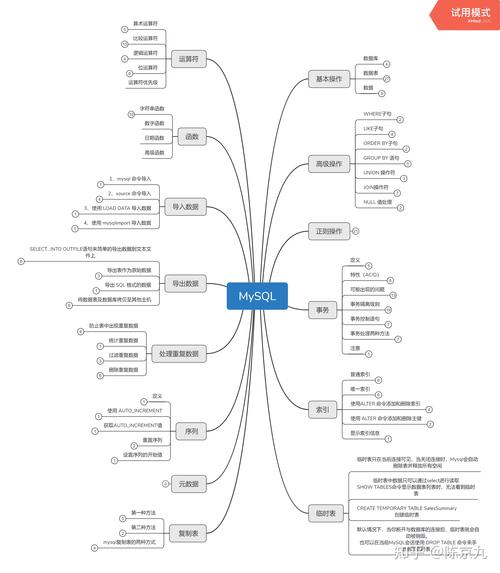

多维视图
在 MySQL 中,可以通过创建视图来模拟多维数据模型的某些特性,视图是虚拟的表,它是通过查询定义的,并且可以像真实的表一样使用,多维视图通常涉及复杂的聚合和连接操作,以展示数据的多个维度。
假设有一个销售数据表sales_data,包含以下字段:product_id,region,sales_date,quantity,我们可以创建一个视图来展示每个产品在不同地区的月度销售总额:
CREATE VIEW monthly_sales AS
SELECT
product_id,
region,
YEAR(sales_date) AS year,
MONTH(sales_date) AS month,
SUM(quantity) AS total_quantity
FROM
sales_data
GROUP BY
product_id,
region,
year,
month; 这个视图将销售数据按产品、地区以及年月分组,并计算每个分组的销售总量。
多维分支
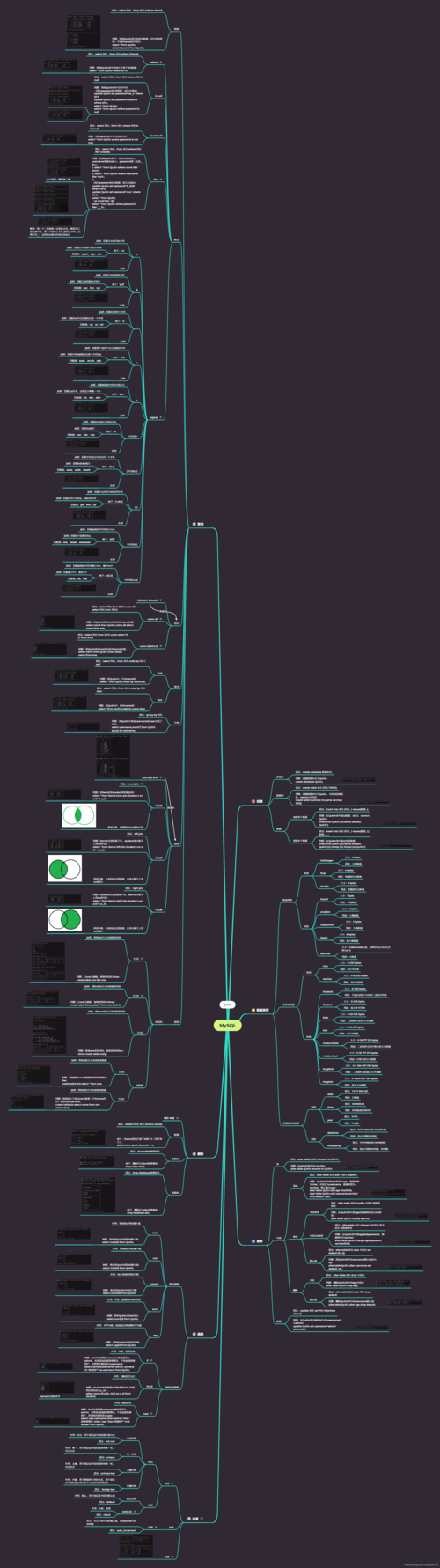
多维分支通常指的是数据仓库中的星型模式(Star Schema)或雪花模式(Snowflake Schema),它们用于优化多维查询,MySQL 本身不直接支持这些模式,但可以通过设计表结构和查询来实现类似的效果。
在星型模式中,有一个事实表(Fact Table)和多个维度表(Dimension Tables),事实表包含量化的业务数据,而维度表包含描述性信息,对于销售数据,sales_fact 可能是事实表,product_dimension、time_dimension 和region_dimension 是维度表。
查询时,可以通过连接这些表来获取多维数据:
SELECT
p.product_name,
r.region_name,
t.year,
t.month,
SUM(s.quantity) AS total_quantity
FROM
sales_fact s
JOIN
product_dimension p ON s.product_id = p.product_id
JOIN
region_dimension r ON s.region_id = r.region_id
JOIN
time_dimension t ON s.sales_date = t.sales_date
GROUP BY
p.product_name,
r.region_name,
t.year,
t.month; 相关问题与解答
Q1: MySQL 是否适合进行大规模的多维数据分析?
A1: MySQL 可以处理一定程度的多维数据分析,特别是当数据量不是特别大时,对于大规模数据集和复杂的多维分析,更专业的解决方案如数据仓库(Amazon Redshift、Google BigQuery)或者专门的OLAP数据库(Apache Kylin、Microsoft SQL Server Analysis Services)可能更加合适。
Q2: 如何提高 MySQL 中多维查询的性能?
A2: 提高性能的方法包括:
优化索引:确保所有用于连接和过滤的列都有适当的索引。
分区表:如果数据量大,可以使用分区表来提高查询速度。
缓存和汇总:对于经常执行的查询,可以预先计算结果并存储,减少实时计算的需求。
硬件升级:增加内存、使用更快的存储设备、提升CPU性能也能提高查询效率。
【版权声明】:本站所有内容均来自网络,若无意侵犯到您的权利,请及时与我们联系将尽快删除相关内容!

发表回复