
多维数据库(multidimensional database, mdd)通常用于数据仓库和在线分析处理(olap),它们支持复杂的查询操作,如上卷、下钻等,在mysql中,虽然没有内置的多维数据库结构,但可以通过设计表结构和sql查询来模拟多维数据库的某些特性。


多维视图
多维视图通常指的是能够展示多个维度的数据视图,在关系型数据库中,我们可以通过星型模式(star schema)或雪花模式(snowflake schema)来实现这种结构。
星型模式(star schema)
星型模式包括一个事实表(fact table),它包含了业务度量值,以及多个维度表(dimension tables),每个维度表代表一个分析维度,一个销售数据的星型模式可能包含如下表格:
1、事实表:sales_fact
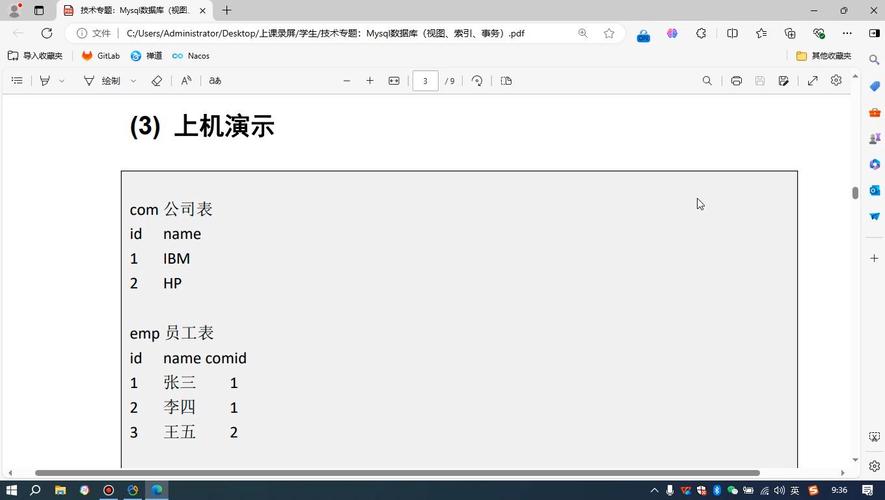
2、维度表:product_dim, time_dim, store_dim, customer_dim
create table sales_fact (
product_id int,
time_id int,
store_id int,
customer_id int,
quantity_sold int,
amount_sold decimal(10, 2),
primary key (product_id, time_id, store_id, customer_id)
);
create table product_dim (
product_id int primary key,
product_name varchar(255),
category varchar(255),
...
);
类似地创建 time_dim, store_dim, customer_dim 表 通过连接这些表,可以构建多维视图,以便于从不同角度分析销售数据。
雪花模式(snowflake schema)
雪花模式是星型模式的变种,它将维度表进一步规范化,分解成多个相关的表,这样做可以减少数据冗余,但会增加查询的复杂性。
多维分支
多维分支通常指的是在多维数据模型中,根据不同的分析需求,沿着某个维度进行深入分析的过程,在mysql中,这通常通过group by和聚合函数实现。
如果我们想要分析不同产品类别的销售情况,可以编写如下sql查询:
select p.category, sum(s.quantity_sold) as total_quantity, sum(s.amount_sold) as total_amount from sales_fact s join product_dim p on s.product_id = p.product_id group by p.category;
这个查询将按照产品类别对销售数量和销售金额进行汇总,从而允许用户“分支”进入产品维度进行深入分析。
相关问题与解答
问题1: 如何优化多维视图的查询性能?
答案1: 优化多维视图的查询性能可以通过以下方法:
索引:确保所有维度表和事实表中经常用于连接和过滤的字段都有合适的索引。
分区:对于非常大的事实表,可以使用分区来改善查询性能。
缓存:使用缓存来存储常用查询结果,减少数据库访问次数。
汇总表:创建汇总表来存储预先计算好的聚合数据,以便快速响应查询。
问题2: mysql是否适合作为多维数据库使用?
答案2: mysql本身是一个关系型数据库管理系统,不是专为多维数据处理设计的,通过上述提到的技术(如星型模式和雪花模式),你可以在mysql中模拟多维数据库的一些功能,对于中小型数据集,这种方法是可行的,但是如果你需要高性能的多维数据分析,可能会需要专业的olap数据库或数据仓库解决方案。
【版权声明】:本站所有内容均来自网络,若无意侵犯到您的权利,请及时与我们联系将尽快删除相关内容!


发表回复