
【大数据比对方案】
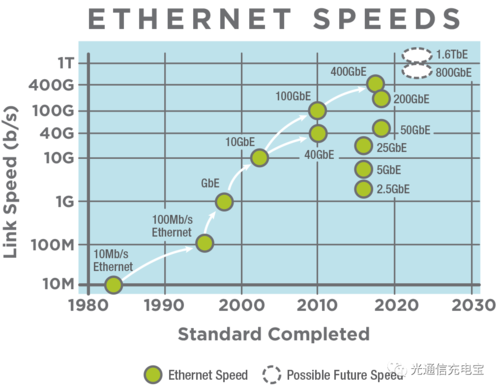

在当今信息爆炸的时代,大数据已经成为了各行各业的重要资源,为了更好地利用这些数据,我们需要对其进行比对和分析,本文将介绍一种大数据比对方案,并回答关于目标比对功能和支持的比对速率的问题。
1、目标比对功能:
目标比对是指将两个或多个数据集进行比较,以找出它们之间的相似性和差异性。
目标比对可以用于各种场景,如数据清洗、数据集成、数据一致性验证等。
通过目标比对,我们可以发现数据中的错误、重复项、缺失值等问题,并进行相应的修复和处理。
2、比对速率:
比对速率是指完成一次比对所需的时间。
比对速率的快慢取决于多个因素,包括数据量的大小、数据的结构和复杂度、比对算法的效率等。
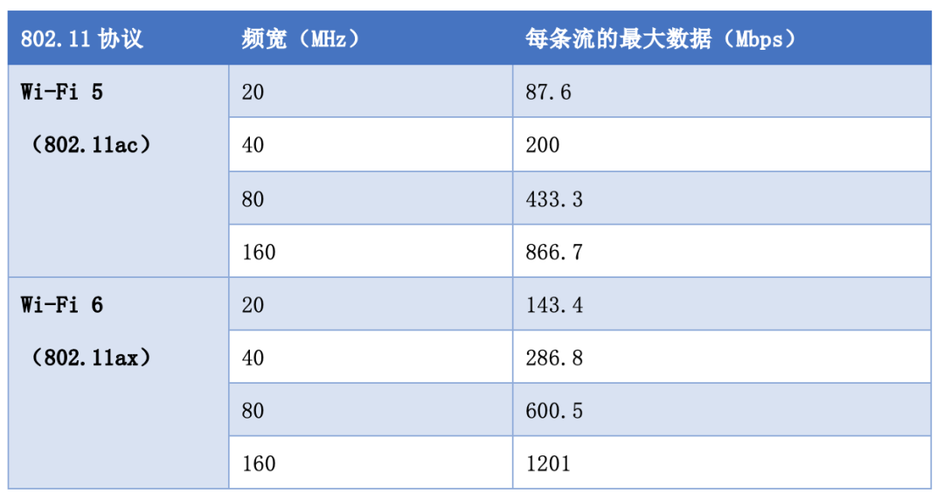
大数据比对的速率较慢,因为需要处理大量的数据和复杂的计算任务。
3、大数据比对方案的关键步骤:
数据预处理:对原始数据进行清洗、转换和标准化,以便进行后续的比对操作。
特征提取:从数据中提取出有意义的特征,作为比对的依据。
相似度度量:计算不同数据集之间的相似度,常用的方法有余弦相似度、欧氏距离等。
结果分析:根据比对结果,分析数据集之间的相似性和差异性,并采取相应的措施进行处理。
4、大数据比对方案的挑战:
数据量大:大数据比对需要处理海量的数据,这对计算资源和存储空间提出了较高的要求。
数据结构复杂:大数据往往具有复杂的结构,如图、树等,这增加了比对的难度和复杂性。
算法效率低:传统的比对算法在处理大规模数据时效率较低,需要采用高效的算法和技术来提高比对速率。
5、解决方案:
并行计算:利用分布式计算框架,将比对任务分解为多个子任务并行执行,以提高比对速率。
索引技术:使用索引技术来加速数据的检索和比对操作,减少不必要的计算和数据传输。
增量比对:采用增量比对的方式,只对比新增加的数据进行比对,减少比对的工作量和时间。
6、相关工具和技术:
Hadoop:一个开源的分布式计算框架,可用于处理大规模的数据集。
Spark:一个快速的大数据处理引擎,支持高效的数据处理和比对操作。
数据库索引技术:如B树、哈希索引等,用于加速数据的检索和比对操作。
7、
大数据比对是一个重要的任务,可以帮助我们发现数据中的问题并进行处理,目标比对功能可以用于各种场景,而比对速率受到多个因素的影响,为了提高比对速率,我们可以采用并行计算、索引技术和增量比对等解决方案,Hadoop、Spark等工具和技术也为我们提供了强大的支持。
与本文相关的问题:
1、如何选择合适的大数据比对方案?
答:选择合适的大数据比对方案需要考虑多个因素,如数据量的大小、数据的结构和复杂度、比对算法的效率等,可以根据具体的需求和场景选择适合的解决方案,并进行评估和测试。
2、如何提高大数据比对的速率?
答:提高大数据比对的速率可以采用并行计算、索引技术和增量比对等解决方案,选择合适的工具和技术也是非常重要的,如Hadoop、Spark等可以提供高效的数据处理和比对操作,优化算法和代码也是提高速率的有效手段。
【版权声明】:本站所有内容均来自网络,若无意侵犯到您的权利,请及时与我们联系将尽快删除相关内容!


发表回复