
在MySQL中,覆盖索引(Covering Index)是一种优化技术,允许查询直接使用索引来获取所需的所有数据,而无需访问表中的记录,当一个查询请求的数据全部包含在索引中时,就可以使用覆盖索引来提高查询性能。


覆盖索引的工作原理
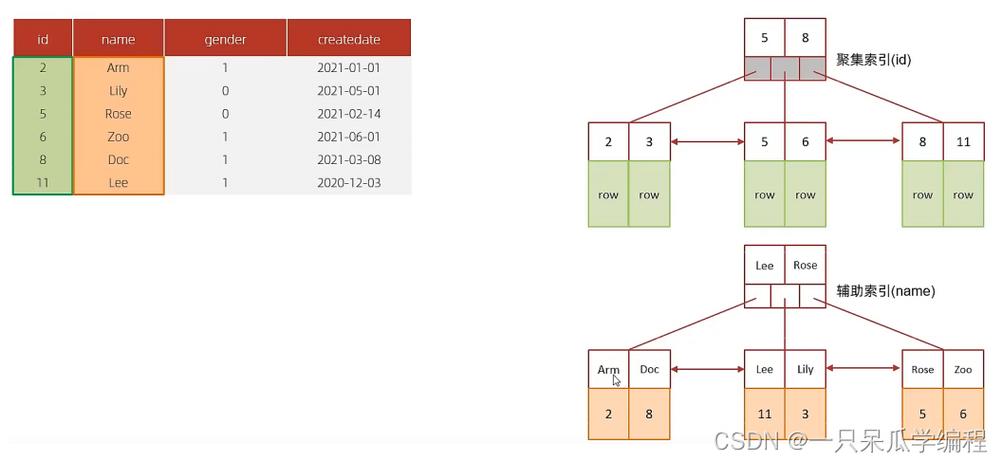
覆盖索引的关键在于索引中存储了查询所需要的全部字段信息,这样数据库引擎就无需回表读取原始数据,在InnoDB存储引擎中,非主键索引(secondary index)会保存主键的值,然后通过主键值来定位完整的行数据,如果查询只需要索引中的信息,那么数据库引擎可以直接返回这些数据而不用去查找表中的行。
如何判断是否使用了覆盖索引
可以通过EXPLAIN命令查看查询执行计划来判断是否使用了覆盖索引,如果Extra列显示为“Using index”,则说明使用了覆盖索引。
创建覆盖索引的步骤
1、分析查询模式: 确定哪些查询最频繁以及这些查询需要哪些字段。
2、选择合适的索引列: 选择那些能够覆盖查询所需字段的列作为索引。
3、创建复合索引: 由于MySQL通常只使用一个索引,因此需要创建一个包含所有必需字段的复合索引。
4、测试和监控: 创建索引后要进行测试,确保它提高了性能,并持续监控其效果。
覆盖索引的优势
减少I/O操作: 不需要回表读取额外数据,减少了磁盘I/O。
提高查询效率: 索引通常比表小得多,因此扫描索引比扫描全表快。
注意事项
维护成本: 额外的索引会增加写操作的成本,因为索引也需要更新。
索引大小: 过大的索引可能会降低查询性能。
选择性: 只有高度选择性的索引才适合做覆盖索引。
示例
假设我们有一个用户表users,表结构如下:
| Column | Type |
| id | int |
| name | varchar(100) |
| varchar(100) | |
| address | varchar(255) |
如果我们经常需要根据邮箱查询用户名和地址,可以创建一个覆盖索引:
CREATE INDEX idx_email_name_address ON users(email, name, address);
查询SELECT name, address FROM users WHERE email = 'someone@example.com';将会使用覆盖索引。
相关问题与解答
问题1: 覆盖索引是否总是提高查询性能?
回答: 不一定,覆盖索引只有在查询完全能够由索引中的字段满足时才有效,如果索引很大或者查询不常用,可能不会带来性能提升。
问题2: 如何平衡覆盖索引的好处和它的成本?
回答: 应该对查询模式进行分析,以确定哪些索引是真正需要的,定期监控索引的效果,并根据实际表现进行调整,对于写密集型的系统,可能需要更加谨慎地添加索引,以避免过多的写操作开销。
【版权声明】:本站所有内容均来自网络,若无意侵犯到您的权利,请及时与我们联系将尽快删除相关内容!

发表回复