
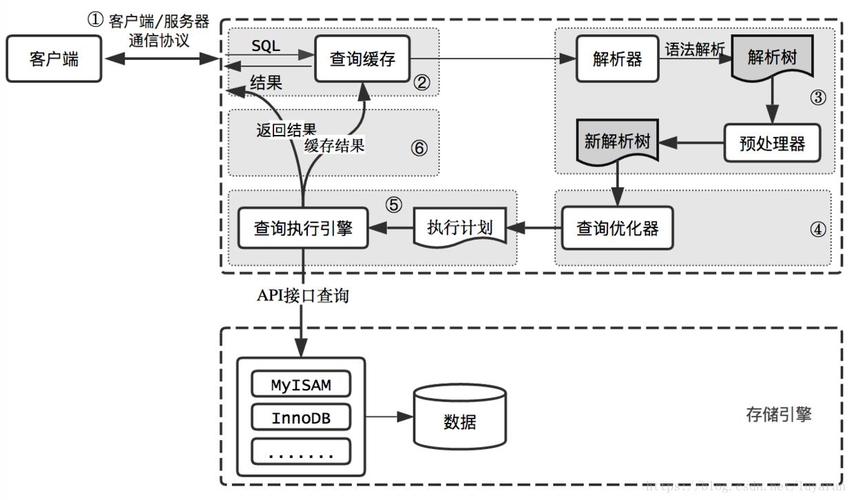
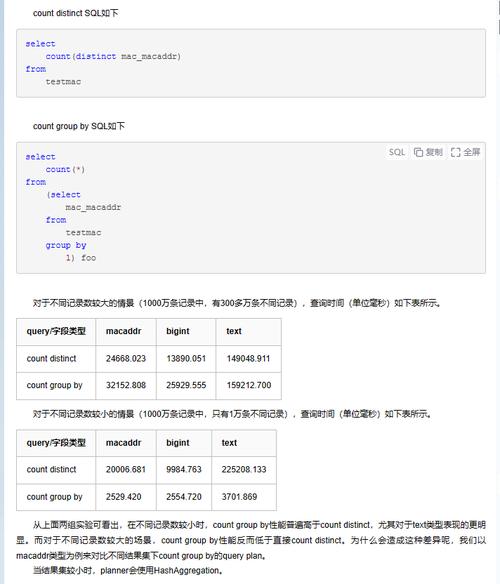
DISTINCT和GROUP BY都可以用于去除重复数据。DISTINCT适用于所有列,而GROUP BY仅适用于分组列。优化方面,GROUP BY通常性能更好,因为MySQL会为分组操作创建临时表。在MySQL数据库中,DISTINCT和GROUP BY是两种常用的SQL语句,用于从表中选择唯一的行,虽然它们都可以实现类似的目标,但在性能和用法上有一些区别,本文将介绍这两种语句的优化方法,并通过实例进行说明。

DISTINCT优化
DISTINCT关键字用于返回唯一不同的值,当表中的数据量很大时,使用DISTINCT可能会导致查询性能下降,为了优化DISTINCT查询,可以采取以下措施:
1、索引优化:为涉及的列创建索引,可以加速DISTINCT查询的执行速度,如果有一个查询SELECT DISTINCT column1 FROM table1,可以为column1创建一个索引。
2、限制列数:尽量减少DISTINCT涉及的列数,因为每增加一个列,查询的性能就会降低,只选择需要的列,避免选择不必要的列。
3、使用子查询:如果需要对多个列应用DISTINCT,可以考虑使用子查询来减少数据量。SELECT DISTINCT column1, column2 FROM (SELECT column1, column2 FROM table1 WHERE condition) AS subquery。
4、分页查询:如果只需要部分结果,可以使用LIMIT和OFFSET进行分页查询,以减少查询的数据量。
GROUP BY优化
GROUP BY用于对结果集按照一个或多个列进行分组,并对每个分组执行聚合函数,如COUNT、SUM、AVG等,以下是一些优化GROUP BY查询的方法:
1、索引优化:类似于DISTINCT,为涉及的列创建索引可以提高GROUP BY查询的性能。
2、选择性分组列:尽量选择具有高选择性的列作为分组列,这样可以减少分组的数量,提高查询性能。
3、使用聚合函数:尽量使用聚合函数而不是GROUP BY来获取相同的结果,使用COUNT(DISTINCT column)而不是GROUP BY column。
4、分页查询:与DISTINCT类似,可以使用LIMIT和OFFSET进行分页查询。
5、避免全表扫描:尽量避免在GROUP BY查询中使用全表扫描,可以通过添加适当的过滤条件来减少查询的数据量。
实例分析
假设有一个销售数据表sales_data,包含以下列:order_id(订单ID)、product_id(产品ID)、quantity(数量)和price(价格)。
示例1:使用DISTINCT获取唯一产品ID
SELECT DISTINCT product_id FROM sales_data;
为了优化这个查询,可以为product_id创建索引。
示例2:使用GROUP BY计算每个产品的总销售额
SELECT product_id, SUM(quantity * price) AS total_sales FROM sales_data GROUP BY product_id;
为了优化这个查询,可以为product_id和quantity、price创建索引,并尽量选择具有高选择性的列作为分组列。
相关问题与解答
问题1:在什么情况下应该使用DISTINCT而不是GROUP BY?
答案:当只需要从结果集中选择唯一的行,而不需要进行任何聚合操作(如计数、求和等)时,应该使用DISTINCT,而当需要对结果集进行聚合操作时,应使用GROUP BY。
问题2:如何确定是否为某个列创建索引以提高查询性能?
答案:可以通过分析查询的执行计划来确定是否需要为某个列创建索引,如果发现某个列的查询成本较高,并且该列被频繁用于过滤或排序操作,那么为该列创建索引可能会提高查询性能。
【版权声明】:本站所有内容均来自网络,若无意侵犯到您的权利,请及时与我们联系将尽快删除相关内容!

发表回复