
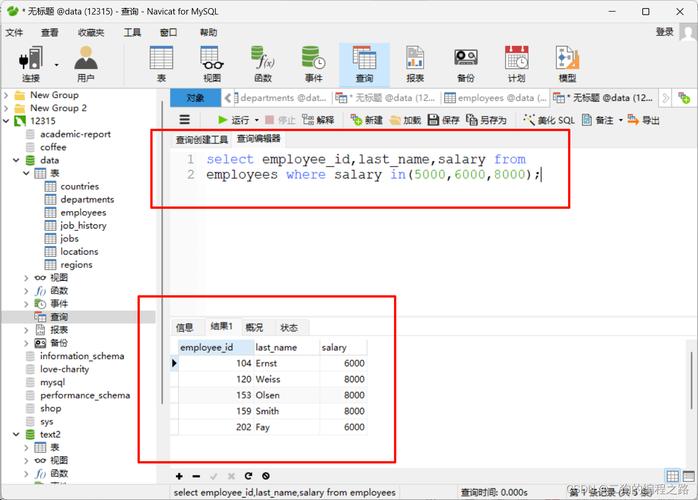
DISTINCT关键字或者利用GROUP BY语句。如果你有一个名为students的表,并且想要去除其中的重复姓名,你可以执行以下查询:,,“sql,SELECT DISTINCT name FROM students;,`,,或者使用GROUP BY:,,`sql,SELECT name FROM students GROUP BY name;,“,,这将返回一个没有重复姓名的列表。在数据库设计和管理中,处理重复数据是一个常见的问题,MySQL数据库提供了多种方法来识别和删除重复的记录,下面介绍如何在MySQL中去除重复数据,并避免未来的数据冗余。

理解重复数据
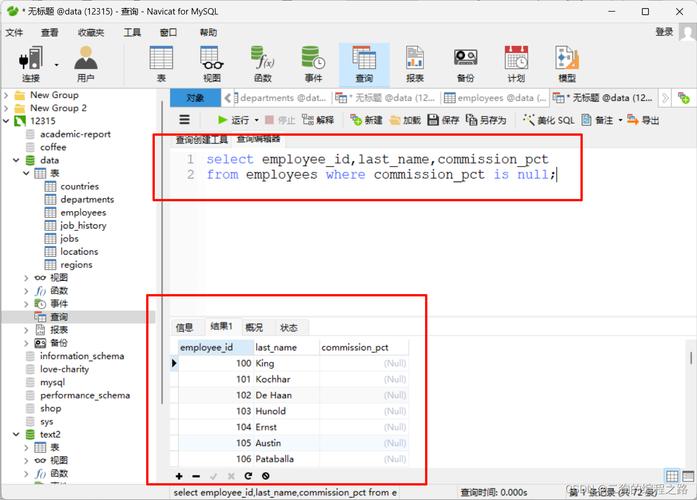
我们需要定义什么是“重复数据”,在数据库上下文中,如果两条或多条记录在某些字段上具有相同的值,则这些记录可能被认为是重复的,一个用户表中可能有多个具有相同电子邮件地址的记录。
查找重复数据
要查找重复的数据,我们可以使用SQL查询,以下是一个例子:
SELECT column_name, COUNT(*) FROM table_name GROUP BY column_name HAVING COUNT(*) > 1;
这个查询会显示每个唯一值的出现次数,从而帮助我们确定哪些值有重复。
删除重复数据
一旦确定了哪些记录是重复的,下一步就是删除它们,这通常涉及到确定哪条记录应该保留,哪条应该删除,一种常见的方法是保留每个重复组中的一条记录,通常是ID最小或最大的那一条。
以下是一个删除除ID最小的记录外的所有重复记录的示例:
DELETE t1 FROM table_name t1
INNER JOIN (
SELECT column_name, MIN(id) as min_id
FROM table_name
GROUP BY column_name
HAVING COUNT(*) > 1
) t2 ON t1.column_name = t2.column_name AND t1.id > t2.min_id; 避免未来数据冗余
为了避免将来的数据冗余,可以采取以下措施:

1、数据库约束:使用唯一约束(UNIQUE)或主键约束(PRIMARY KEY)确保特定列的值是唯一的。
2、应用程序逻辑:在插入新记录之前检查是否存在重复项,并据此采取行动。
3、定期清理:定期运行去重脚本以维护数据的清洁性。
相关表格
| 动作 | SQL命令 | 描述 |
| 查找重复 | SELECT column_name, COUNT(*) FROM table_name GROUP BY column_name HAVING COUNT(*) > 1; | 找出所有重复的记录 |
| 删除重复 | DELETE t1 FROM table_name t1 INNER JOIN (SELECT column_name, MIN(id) as min_id FROM table_name GROUP BY column_name HAVING COUNT(*) > 1) t2 ON t1.column_name = t2.column_name AND t1.id > t2.min_id; | 删除除ID最小的之外的重复记录 |
相关问题与解答
Q1: 如果我不想删除任何数据,只想查看哪些记录是重复的,我应该怎么办?
A1: 你可以使用上述查找重复数据的SQL查询来查看哪些记录是重复的,而不实际删除它们,这将给你一个列表,显示每个重复值及其出现的次数。
Q2: 如果我有一个更复杂的表结构,有多列需要一起判断是否重复,我该如何修改查询?
A2: 如果你需要根据多个列来判断记录是否重复,你可以在GROUP BY子句中包含所有这些列,如下所示:
SELECT column1, column2, COUNT(*) FROM table_name GROUP BY column1, column2 HAVING COUNT(*) > 1;
这将返回那些在column1和column2上同时具有相同值的记录组,对于删除操作,你也需要相应地调整子查询和连接条件。
【版权声明】:本站所有内容均来自网络,若无意侵犯到您的权利,请及时与我们联系将尽快删除相关内容!


发表回复