
在探讨ModelArts平台进行文本分类的详细流程与应用时,可以发现这一华为云服务平台为开发者提供了一个全面的解决方案,从数据处理到模型部署都能在这一平台上完成,小编将详细介绍ModelArts平台如何实现文本分类任务的每个关键步骤,以及相关的操作指南。
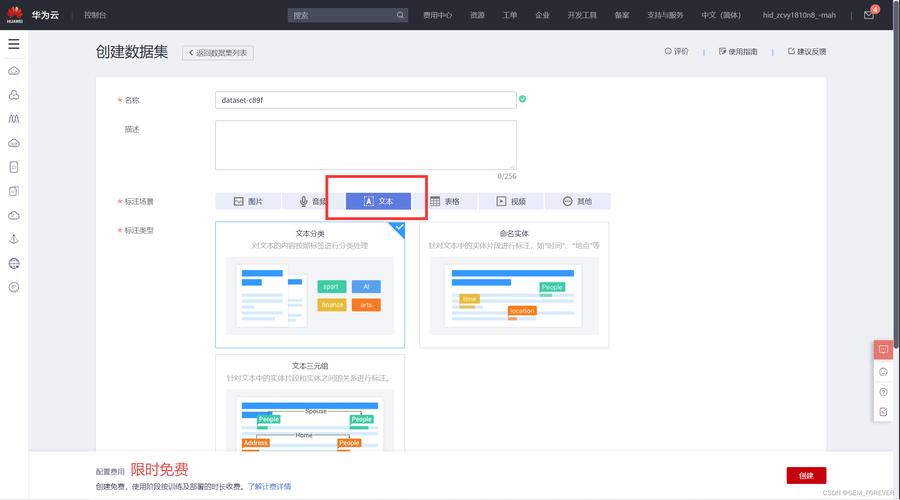

1、准备工作
数据标注:文本分类的第一步是数据标注,确保每个文本都准确地被分配到指定的类别中,ModelArts支持多标签标注,即一个文本可以同时属于多个分类,标注的正确性和多样性直接影响模型的训练效果和最终的应用性能。
数据要求:为了开始训练,每种分类的文本数应该不少于20个,这保证了数据的多样性和丰富性,有助于提升模型的泛化能力。
2、模型训练与评估
训练启动:在ModelArts平台上,用户可以直接上传标注好的文本数据,并启动模型训练,平台提供了多种预训练的模型选项,如基于Bert的中文文本分类算法。
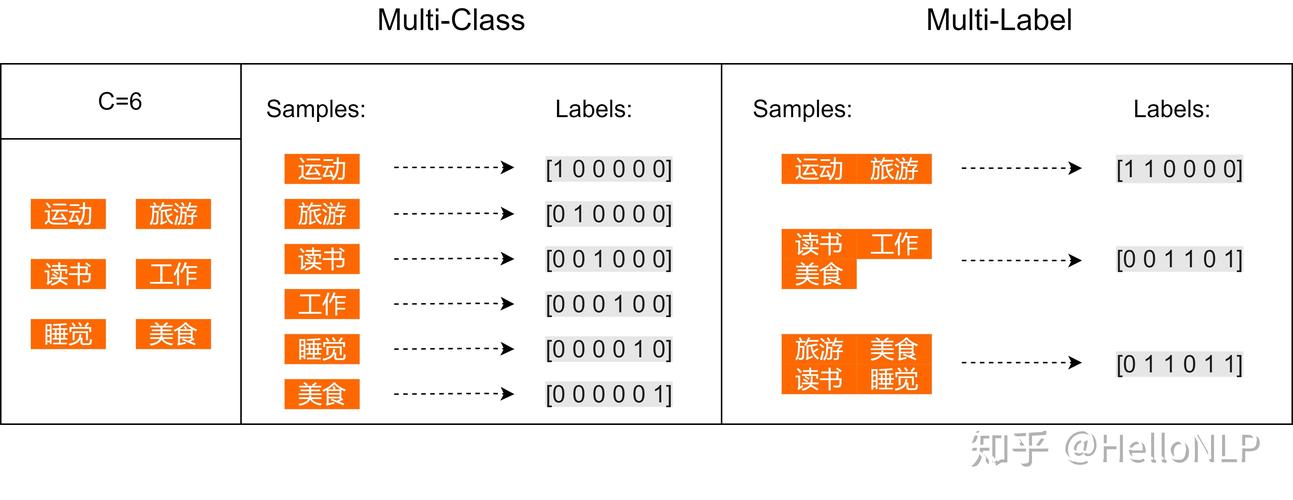
自动化模型生成:ModelArts支持自动化模型生成,减少了人工编码的需要,使得即使是没有深厚技术背景的用户也能轻松训练模型。
性能评估:训练完成后,平台提供工具对模型的性能进行评估,如准确率、召回率等指标,帮助用户了解模型在实际应用场景中的表现。
3、模型部署
在线服务部署:一旦模型被训练和评估,下一步是将其部署为在线服务,以便实时处理新的文本数据,ModelArts支持将模型部署到云端,实现高效的运算和服务响应。
按需部署:ModelArts支持端边云模型按需部署,这意味着用户可以根据实际情况选择在不同场景下使用不同级别的计算资源。
4、数据管理与权限设置
数据管理工具:ModelArts提供数据管理模块,允许用户高效地管理训练数据和标注作业,此模块在平台的左侧菜单栏中易于访问。
权限定制:对于未使用过数据管理功能的新用户,ModelArts可能需要通过提交工单来开通相应权限。
5、算法与市场集成
AI Gallery集成:ModelArts与华为云的AI Gallery紧密集成,允许用户直接订阅和使用市场上的最新文本分类算法,如基于Bert的算法。
在深入理解ModelArts平台如何助力文本分类后,还需要注意以下实际应用中的关键点:
保证数据质量和多样性是成功训练模型的前提。
正确设置模型参数可以显著影响模型的学习效率和输出质量。
定期评估和调整模型是维持其高性能的关键。
归纳而言,ModelArts平台为文本分类任务提供了一个端到端的解决方案,从数据预处理到模型部署,每一步都设计有用户友好的操作界面和强大的自动化工具,利用这个平台,即便是非专业的开发者也能快速实现文本分类任务的部署和应用。
相关问题与解答
ModelArts平台是否支持自定义模型训练?
ModelArts不仅提供了零代码模型训练方案,也支持开发者上传自己的模型进行训练,这意味着用户可以根据自己的特定需求,开发并训练自定义模型。
如何确保数据标注的质量?
数据标注的质量直接影响模型的训练结果,确保数据标注的质量可以通过多种方式实现,例如使用专业的数据标注团队,定期审核标注数据,以及使用ModelArts提供的智能标注工具来辅助人工标注过程。
【版权声明】:本站所有内容均来自网络,若无意侵犯到您的权利,请及时与我们联系将尽快删除相关内容!


发表回复