
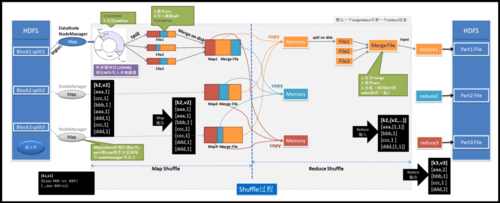
MapReduce是一种编程模型,用于处理和生成大数据集,它包含两个主要阶段:Map阶段和Reduce阶段,Map阶段的任务是处理输入数据并生成一组中间键值对,而Reduce阶段则负责将这些中间数据整合起来以得到最终结果。

Map接口
在MapReduce中,Map接口定义了如何将输入数据转换成中间键值对,实现Map接口的类需要重写map方法,该方法接收一个键值对作为输入,并产出零个或多个键值对作为输出。
输入与输出
输入:Map操作的输入是一系列键值对,通常来自输入文件的一个数据块。
输出: 输出是零个或多个中间键值对,这些键值对不需要保持有序。
工作原理
1、读取输入数据:Map任务从输入文件中读取数据。
2、数据转换:通过用户自定义的map函数,将每条输入记录转换为零个或多个键值对。
3、排序与分区:MapReduce框架会自动对这些中间键值对进行排序,并将它们按照键分组,准备传递给Reduce阶段。
代码示例

public static class MyMapper extends Mapper<Object, Text, Text, IntWritable> {
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(Object key, Text value, Context context) throws IOException, InterruptedException {
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens()) {
word.set(itr.nextToken());
context.write(word, one); // 输出键值对
}
}
} 在这个Java的例子中,我们定义了一个MyMapper类,它从文本行中解析单词,并为每个出现的单词输出一个键值对(单词,1)。
Reduce接口
Reduce接口定义了如何合并具有相同键的所有中间值,实现Reduce接口的类需要重写reduce方法。
输入与输出
输入:Reduce操作的输入是由Map阶段产生的、按键分组的一系列键值对。
输出: 对于每个唯一的键,Reduce操作产生零个或一个输出值。
工作原理
1、读取Map输出:Reduce任务从Map任务的输出中读取数据。
2、合并值:使用用户定义的reduce函数,将所有共享同一个键的值集合合并成一个更小的值集合。
3、输出结果:输出最终的键值对。
代码示例
public static class MyReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
private IntWritable result = new IntWritable();
public void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get(); // 累加值
}
result.set(sum);
context.write(key, result); // 输出结果
}
} 这个例子中的MyReducer类会计算每个单词出现的次数,并输出每个单词及其总计数。
相关问题与解答
问题1: MapReduce如何处理大数据?
答案: MapReduce通过将工作分配给多个节点来并行处理大数据,输入数据被分成小块,每个Map任务处理一块数据,并产生中间键值对,Reduce任务汇总这些中间数据,生成最终结果,这种分布式处理允许MapReduce高效地处理非常大的数据集。
问题2: Map和Reduce阶段是否可以并行执行?
答案: 是的,Map和Reduce阶段可以并行执行,MapReduce框架的设计就是为了利用这种并行性,当Map任务完成其工作后,Reduce任务就可以开始处理已排序和分组的中间数据,即使此时仍有其他Map任务在运行,这种并行处理机制显著提高了数据处理速度。
【版权声明】:本站所有内容均来自网络,若无意侵犯到您的权利,请及时与我们联系将尽快删除相关内容!


发表回复