
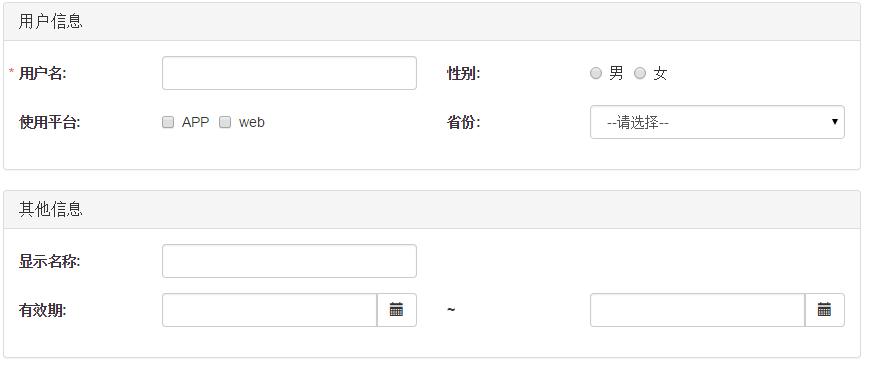
【分块表单配置_配置SparkSQL的分块个数】

在处理大规模数据时,使用SparkSQL进行数据分析和查询是非常常见的,当数据量非常大时,一次性加载整个数据集可能会导致内存溢出或性能问题,为了解决这个问题,可以使用SparkSQL的分块功能将数据集分成多个小块进行处理,本单元将详细介绍如何配置SparkSQL的分块个数。
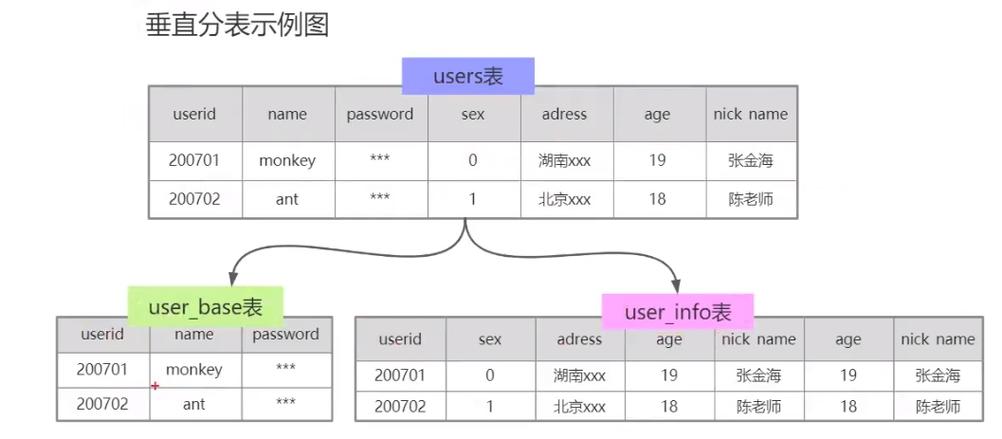
1、分块表单配置的意义
在处理大规模数据时,使用分块表单配置可以将数据集分成多个小块进行处理,从而提高查询性能和减少内存消耗,通过控制每个分块的大小,可以平衡计算资源的利用率和查询效率。
2、分块表单配置的步骤
下面是配置SparkSQL分块个数的步骤:
a. 导入相关模块:
“`python
from pyspark.sql import SparkSession
“`
b. 创建SparkSession对象:
“`python
spark = SparkSession.builder
.appName("Configure Spark SQL Chunking")
.getOrCreate()
“`
c. 读取数据集:
“`python
data = spark.read
.format("csv")
.option("header", "true")
.load("data.csv")
“`
d. 配置分块个数:
“`python
chunkSize = 1000000 # 每个分块的大小(行数)
numOfChunks = data.count() // chunkSize + (1 if data.count() % chunkSize != 0 else 0) # 计算分块个数
“`
e. 将数据集分割成多个分块:
“`python
data = data.rdd.getNumPartitions()
.mapPartitionsWithIndex(lambda index, iter: iter[index::numOfChunks])
.toDF()
“`
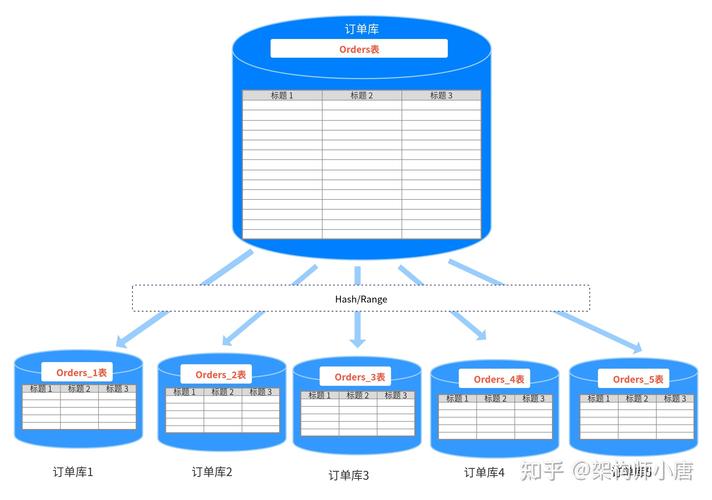
3、分块表单配置的注意事项
a. 合理选择分块大小:分块大小的选择应该根据数据集的大小和计算资源的情况来确定,如果分块太小,会导致过多的小任务和网络传输开销;如果分块太大,可能会导致单个任务过大,无法充分利用计算资源,可以根据数据集的大小和内存容量来估算合适的分块大小。
b. 考虑并行度:除了设置分块大小,还需要考虑并行度的配置,通过调整并行度,可以进一步优化查询性能,并行度应该与集群中的可用核心数相匹配,可以通过spark.default.parallelism属性来设置默认的并行度。
4、示例代码展示
下面是一个示例代码,演示了如何使用SparkSQL进行分块查询:
“`python
from pyspark.sql import SparkSession
spark = SparkSession.builder
.appName("Configure Spark SQL Chunking")
.getOrCreate()
# 读取数据集并配置分块个数和并行度
data = spark.read
.format("csv")
.option("header", "true")
.option("inferSchema", "true")
.option("sep", ",")
.load("data.csv")
.repartition(10)
.write
.format("csv")
.mode("overwrite")
.save("chunked_data/data")
# 执行分块查询
queryResult = spark.sql("SELECT * FROM chunked_data.data")
.collect()
print(queryResult)
“`
5、归纳
通过配置SparkSQL的分块个数,可以将大规模数据集分成多个小块进行处理,提高查询性能和减少内存消耗,在配置分块个数时,需要根据数据集的大小和计算资源的情况选择合适的分块大小,并考虑并行度的配置,以上是关于配置SparkSQL分块个数的详细说明。
【与本文相关的问题及解答】
1、Q: SparkSQL的分块功能有什么作用?
A: SparkSQL的分块功能可以将大规模数据集分成多个小块进行处理,从而提高查询性能和减少内存消耗,通过控制每个分块的大小,可以平衡计算资源的利用率和查询效率。
2、Q: 如何确定合适的分块大小?
A: 合适的分块大小应该根据数据集的大小和计算资源的情况来确定,如果分块太小,会导致过多的小任务和网络传输开销;如果分块太大,可能会导致单个任务过大,无法充分利用计算资源,可以根据数据集的大小和内存容量来估算合适的分块大小。
【版权声明】:本站所有内容均来自网络,若无意侵犯到您的权利,请及时与我们联系将尽快删除相关内容!


发表回复