
在数据库管理中,有时需要对数据进行随机更新以模拟某些场景或测试系统性能,MySQL提供了多种方式来实现数据的随机更新,随机森林回归作为一种集成学习方法,在处理回归问题时表现出色,本文将探讨如何在MySQL中进行随机更新,并简要介绍随机森林回归模型。

MySQL中的随机更新
在MySQL中进行随机更新通常涉及使用内置的函数和表达式来生成随机值,以下是一些常见的方法:
使用RAND()函数
RAND()函数可以生成0到1之间的随机浮点数,要随机更新表中的数据,可以将此函数与UPDATE语句结合使用,如果你想随机设置某列的值在一定范围内,你可以这样做:
UPDATE your_table SET your_column = FLOOR(1 + RAND() * (100 1)) WHERE some_condition;
这将your_column的值更新为1到100之间的一个随机整数。
使用UUID()函数
UUID()函数生成一个全局唯一的标识符(UUID),虽然它主要用于生成唯一ID,但也可以用于生成随机字符串。
UPDATE your_table SET your_string_column = SUBSTRING(UUID(), 1, 8) WHERE some_condition;
这将your_string_column更新为一个随机的8字符长的字符串。
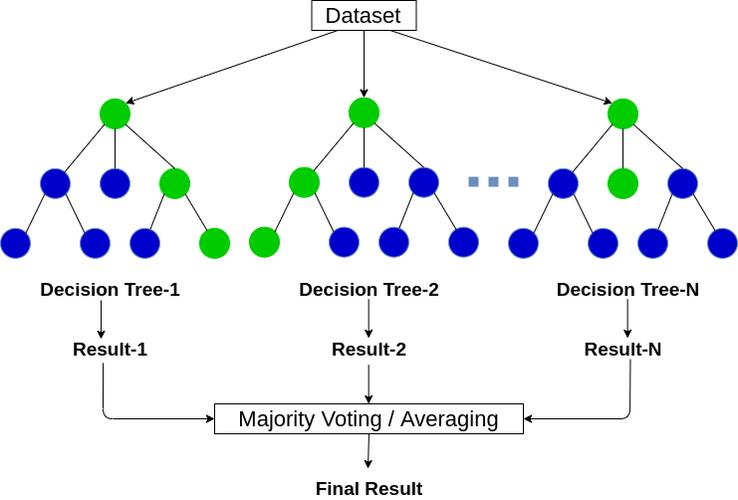
随机森林回归简介
随机森林是一种集成学习技术,它构建多个决策树并将它们的输出进行平均以改善预测精度和控制过拟合,随机森林回归专注于连续值的预测。
如何工作
随机森林回归通过以下步骤工作:
1、自助采样:从原始数据集中重复随机选择样本来构建子数据集,这称为自助采样(bootstrap sampling)。
2、构建决策树:对于每个子数据集,构建一个决策树,允许每个节点使用随机选定的特征子集。
3、聚合结果:所有决策树的预测结果被平均(回归任务)或多数投票(分类任务),以产生最终的预测结果。
优点
准确性:随机森林通常能够提供很高的预测准确性。
鲁棒性:由于其构建过程的随机性,随机森林不易受到噪声数据的干扰。
特征重要性评估:随机森林可以提供关于哪些特征对模型影响最大的信息。
相关问题与解答
Q1: 如何在MySQL中使用自定义的随机函数进行更新?
A1: 如果你有自定义的随机函数或算法,你可以通过创建一个存储过程来封装这个逻辑,然后在UPDATE语句中使用这个存储过程来更新数据。
DELIMITER //
CREATE PROCEDURE UpdateWithCustomRandom(IN id INT)
BEGIN
DECLARE randomValue INT;
在这里实现你的随机逻辑,
SET randomValue = CUSTOM_RANDOM_FUNCTION();
UPDATE your_table
SET your_column = randomValue
WHERE id = id;
END //
DELIMITER ;
调用存储过程来更新特定行
CALL UpdateWithCustomRandom(1); Q2: 随机森林回归模型在实际应用中有哪些局限性?
A2: 尽管随机森林是一个强大的工具,但它也有一些局限性:
解释性差:由于模型是基于多个决策树的集合,因此难以解释单个决策树的贡献。
计算成本高:训练随机森林模型可能需要大量的计算资源,特别是当数据集很大或树的数量很多时。
过拟合风险:如果树的数量过多,模型可能会开始过拟合数据,尤其是当单个决策树深度较大时。
【版权声明】:本站所有内容均来自网络,若无意侵犯到您的权利,请及时与我们联系将尽快删除相关内容!

发表回复