
MongoDB分布式部署详解

基本概念
在当今大数据时代,传统单一数据库已经无法满足业务对性能、稳定性与扩展性的要求,MongoDB作为一个流行的NoSQL数据库,通过其分布式部署能力,提供了高可用性与高性能的解决方案。
单机部署与主从部署
单机部署:是MongoDB最基础的部署模式,适用于开发测试环境或数据量较小的情况,只需启动mongod实例,指定数据存储路径和端口即可运行。
主从部署:至少包含一个主节点和一个或多个从节点,主节点处理写操作,从节点则不断同步主节点的数据,以支持读操作和故障恢复。
副本集部署
概念与原理:副本集由一个主节点和多个从节点组成,主节点负责处理客户端请求,从节点复制主节点数据,当主节点出现问题时,系统会自动选举一个新的主节点继续服务。
部署步骤:先为每个节点创建数据存储目录,然后分别启动主节点和从节点的mongod进程,通过replSet参数指定副本集名称。
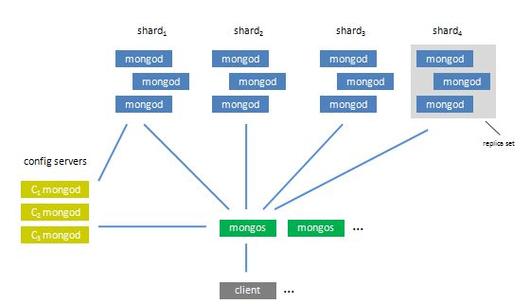
分片部署
架构理解:分片部署是MongoDB实现水平扩展的高级部署方式,允许跨多台服务器分布数据,包括Config Server、Shard Server和Route Server(mongos)三部分。
具体实施:每个Shard可以是一个副本集,保证数据块的高可用,Config Server存储所有Shard的元数据配置,而mongos作为查询路由,负责将请求分发至正确的Shard。
分布式集群的整体架构
在实际生产环境中,MongoDB的集群架构是分布式的,结合了副本集和分片机制来保证生产过程的高可靠性和高可扩展性,整个生产集群与分片集群的架构类似,由三个重要组件组成,包括Shard Server、Config Server和Route Server。
核心组件
Shard Server:由包含三个mongod实例的副本集组成,避免单一实例故障导致数据丢失。
Config Server:也可由多个mongod实例集群组成,保证集群配置信息可用性。
Route Server (mongos):可以使用多个mongos实例,确保客户端请求得到及时响应。
通过以上分布式集群的部署了解MongoDB的副本集和分片机制,假设有三台机器,操作系统为Ubuntu 16.04,均安装了MongoDB 3.4,信息如下表所示,在这三台机器上部署副本集和部署分片集群。
优化策略
在规划MongoDB集群的时候,可以从以下几点进行优化:
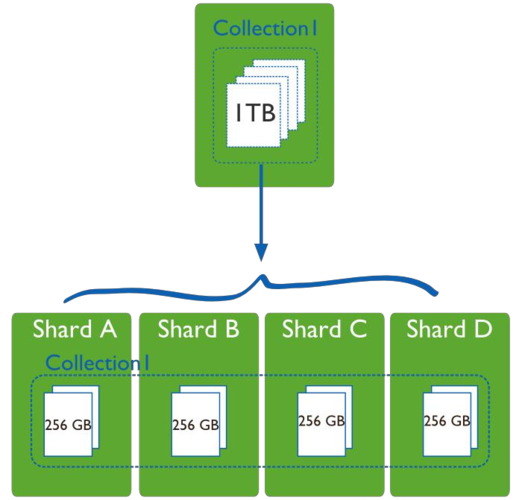
Chunk大小设置:Shard在存储数据时会将数据分成Chunk块存储,每个Chunk默认64MB,可以在初始化时指定Chunks的初始数量,最大为8192,一般情况下,每个Shard在存储的数据量不超过512GB不会发生分裂,保持良好的读写性能。
均衡数据分布:由于数据是通过Hash方式进行分片,因此数据分布相对均匀,在规划集群时,设置Shard的数量可以简单地用预估的总数据量除以500GB,得出要部署的Shard数量。
写入优化:mongos在插入数据过程中主要经历两个磁盘写入步骤:第一次是在指定的时间间隔内写入预写日志,第二次是定时把内存中的数据刷新到磁盘,这些参数可以根据实际业务需求进行调整。
相关问题与解答
Q1: 在分布式部署中,如何保证数据一致性?
A1: MongoDB通过副本集来实现数据的一致性,副本集中的主节点负责写操作,从节点则不断同步主节点的数据,即使主节点出现故障,通过自动故障转移机制,系统仍然能保证数据的一致性。
Q2: 如何监控和调优MongoDB集群的性能?
A2: 可以使用MongoDB自带的性能监控工具,如mongostat和mongotop,定期检查集群的状态和性能指标,通过调整Chunk大小、合理配置硬件资源和网络设置,也可以有效提升集群性能。
MongoDB的分布式部署提供了强大的灵活性和高可用性,能够满足现代应用程序对数据库系统的复杂要求,通过合理规划和持续优化,可以构建出既可靠又高效的分布式数据库系统。
【版权声明】:本站所有内容均来自网络,若无意侵犯到您的权利,请及时与我们联系将尽快删除相关内容!


发表回复