
MapReduce是一种编程模型和用于大规模数据处理的实现框架,由谷歌提出并广泛应用于分布式系统,它的核心思想是将大任务分解为多个小任务,这些小任务可以并行处理,然后再将结果合并以得到最终输出。

MapReduce用户接口介绍
1. Mapper接口
Mapper的任务是处理输入数据并产生中间键值对,用户需要实现map()函数来定义如何从输入数据中提取键值对,Mapper会接收输入数据,通常是文本文件中的一行文本,然后将其转换为一个或多个键值对。
2. Reducer接口
Reducer的任务是处理由Mapper产生的中间键值对,并生成最终结果,用户需要实现reduce()函数来聚合具有相同键的值,Reducer会接收到一个键和对应的值列表,并将它们合并成一个较小的值集合。
3. Driver接口
Driver是MapReduce作业的入口点,负责作业的配置和执行,它设置作业的各种参数,如输入输出路径、Mapper和Reducer类等,并启动MapReduce作业。
4. Partitioner接口(可选)
在某些情况下,可能需要自定义Partitioner来控制如何将中间键值对分配给Reducer,这可以通过实现getPartition()方法来完成,该方法决定给定键应该发送到哪个Reducer。
5. InputFormat和OutputFormat接口(可选)
InputFormat负责定义如何读取输入数据,而OutputFormat定义了如何写入输出数据,这两个接口允许用户根据需要定制数据的读写方式。
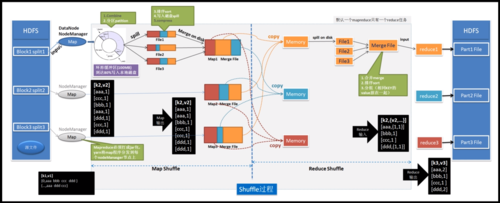
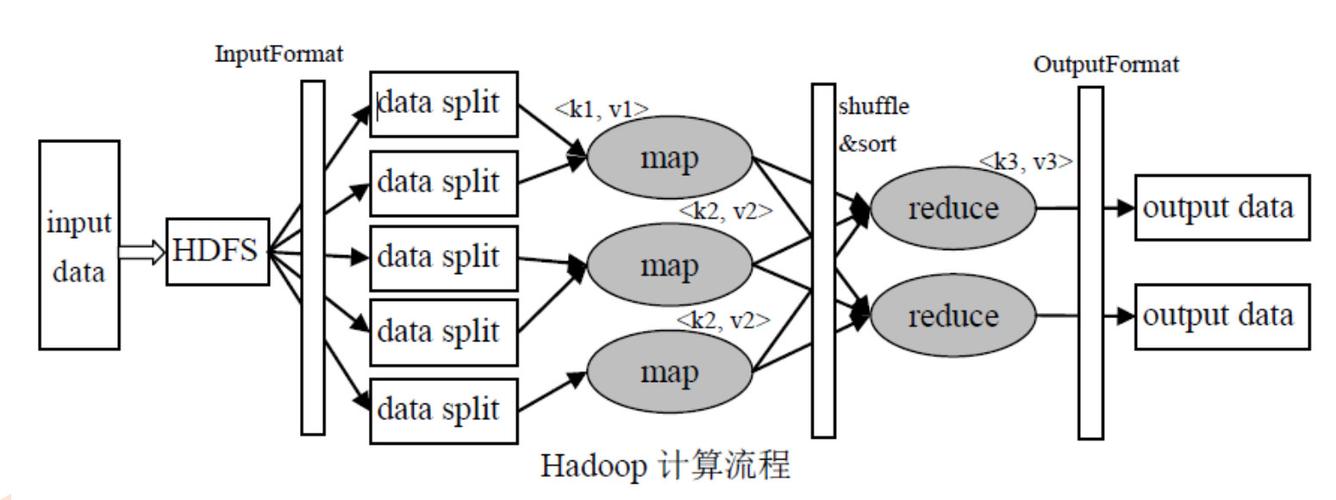
MapReduce数据流
在MapReduce程序中,数据流通过以下步骤进行:
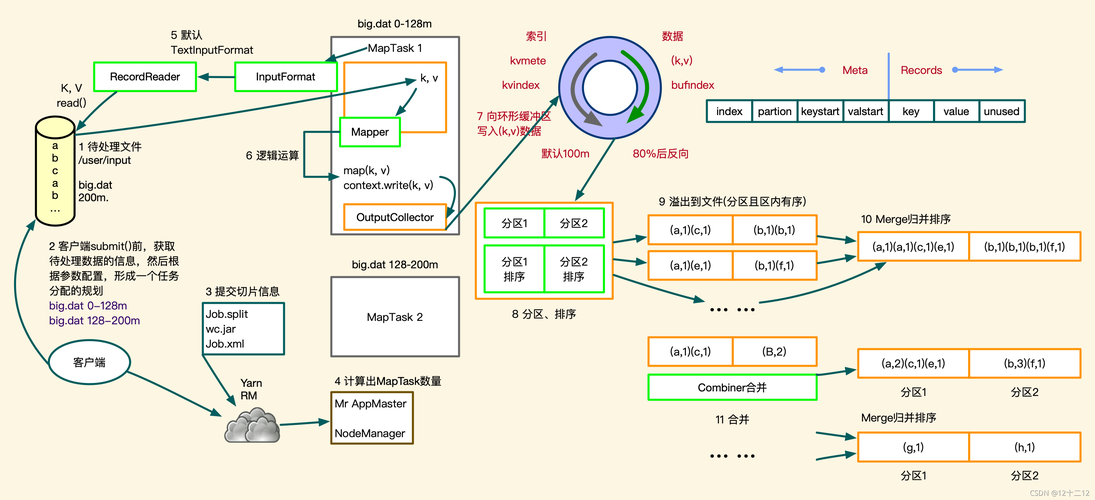
1、输入分片:输入数据集被分成若干个数据片,每个数据片由一个Mapper处理。
2、映射阶段:每个Mapper读取一个数据片,解析出键值对,并传递给用户定义的map()函数进行处理。
3、分区:中间键值对经过分区操作,根据键被分配到不同的Reducer。
4、排序和洗牌:系统对键值对按键进行排序,并且将具有相同键的值传输给同一个Reducer。
5、归约阶段:Reducer接收到所有相关键值对后,调用用户定义的reduce()函数处理数据并输出最终结果。
6、输出:最终结果被写入到输出文件中,可以在分布式文件系统中访问。
相关问题与解答
问题1: MapReduce框架如何处理故障恢复?
答案: MapReduce框架设计时考虑了硬件故障的可能性,因此内置了故障恢复机制,对于Mapper和Reducer任务失败,框架会自动重新调度失败的任务到其他节点上执行,MapReduce还会对数据进行备份,以防数据丢失导致的任务失败。
问题2: 如何优化MapReduce作业的性能?
答案: 优化MapReduce作业性能有多种方法,包括但不限于:合理设置Mapper和Reducer的数量,避免数据倾斜;使用压缩技术减少数据传输量;选择合适的数据格式以加快数据处理速度;以及优化算法逻辑以减少计算复杂性,合理配置集群资源,如内存和CPU,也是提高性能的关键因素。
【版权声明】:本站所有内容均来自网络,若无意侵犯到您的权利,请及时与我们联系将尽快删除相关内容!

发表回复