
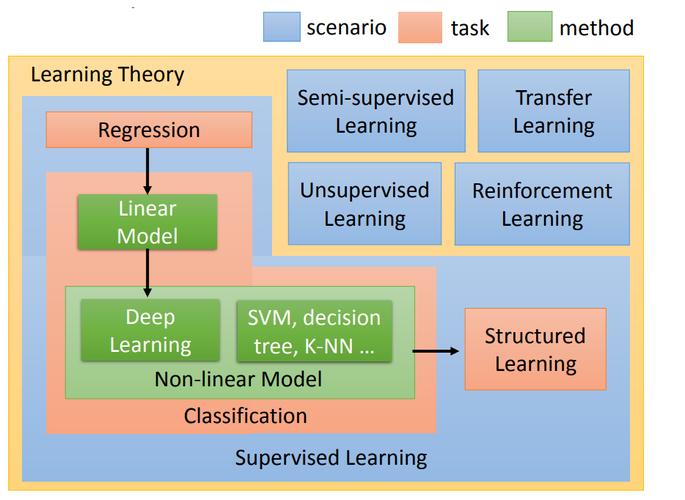
FCM(模糊C均值聚类)是一种基于模糊数学理论的聚类算法,适用于数据集中存在噪声和不完整信息的情况。在机器学习端到端场景中,FCM可以用于数据预处理、特征提取等步骤,提高模型的准确性和鲁棒性。
FCM(Firefly Clustering Algorithm)是一种基于萤火虫算法的聚类方法,而机器学习中的端到端学习是指从原始输入数据到最终输出结果的学习过程,中间不经过人工设计的特征提取或其他中间步骤,在端到端学习中,一个单一的神经网络模型可以完成整个任务,无需人工干预或手动设计特征。

(图片来源网络,侵删)
以下是使用FCM进行机器学习端到端场景的详细解释:
1、数据预处理:您需要准备数据集,这可能包括数据清洗、缺失值处理和标准化等步骤,确保数据集是干净、完整且适合用于训练模型。
2、模型选择:选择适当的机器学习模型,对于分类问题,您可以选择决策树、支持向量机、神经网络等,对于回归问题,您可以选择线性回归、岭回归等。
3、特征工程:在传统的机器学习流程中,特征工程是一个关键的步骤,但在端到端学习中,您可以省略这一步,模型将自动从原始数据中学习和提取有用的特征。
4、模型训练:使用训练数据对选定的模型进行训练,在训练过程中,模型将自动调整其参数以最小化误差。
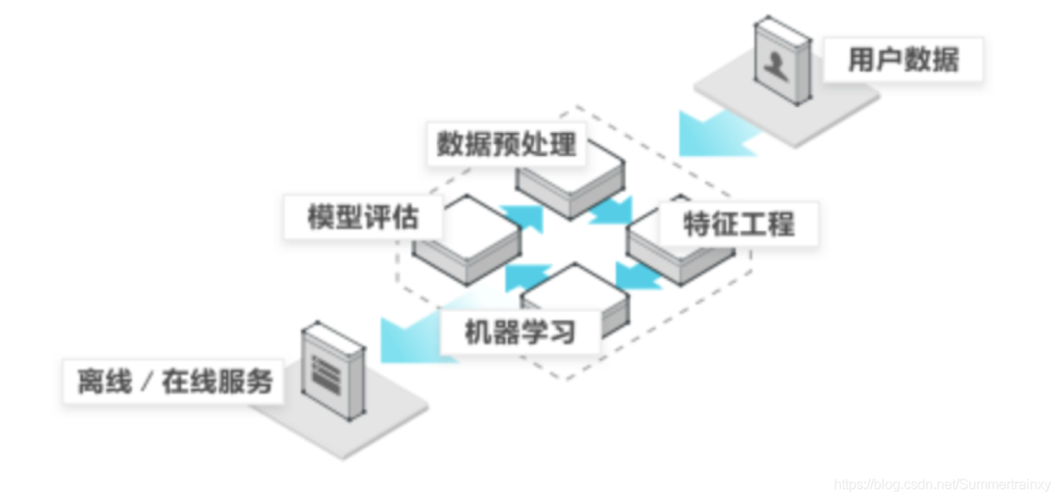
5、模型评估:使用验证集或测试集评估模型的性能,常见的评估指标包括准确率、精确率、召回率、F1分数等。
6、模型优化:根据评估结果,您可以尝试调整模型的超参数、增加更多的训练数据、使用正则化技术等来优化模型性能。
7、部署模型:一旦模型达到满意的性能水平,您可以将其部署到生产环境中,用于实际的预测任务。
(图片来源网络,侵删)
8、监控和维护:持续监控模型的性能,并根据需要进行定期更新和维护,以确保模型保持高效和准确 。
(图片来源网络,侵删)
【版权声明】:本站所有内容均来自网络,若无意侵犯到您的权利,请及时与我们联系将尽快删除相关内容!


发表回复