
模型管理是一个涉及创建、维护、部署和监控机器学习模型的全面过程,它确保了模型在生产环境中的稳定性、可靠性和性能,良好的模型管理实践可以显著提高模型的生命周期,减少维护成本,并确保持续交付价值。

模型开发
1. 数据准备与预处理
收集:从各种来源搜集数据,如数据库、文件系统或实时数据流。
清洗:处理缺失值、异常值和重复记录。
转换:标准化、归一化、编码分类变量等。
2. 特征工程
选择:确定对预测任务最有用的特征。
构造:基于现有数据构建新的特征。
降维:使用PCA、自动编码器等技术减少特征数量。
3. 模型训练与验证
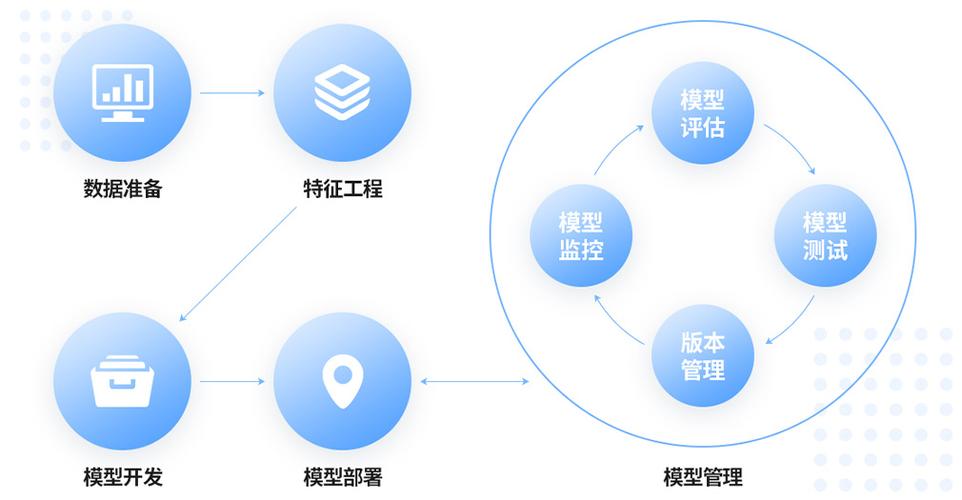
选择算法:根据问题类型选择合适的机器学习算法。
调参:通过交叉验证等方法调整模型参数。
验证:使用独立数据集评估模型性能。
4. 模型优化
集成学习:应用bagging、boosting或stacking提高模型稳定性和准确性。
超参数优化:使用网格搜索、随机搜索或贝叶斯优化进一步调整超参数。
模型部署
1. 模型封装
API设计:设计RESTful API或其他接口以供调用。
容器化:使用Docker等工具将模型及其依赖打包。
2. 持续集成与部署
CI/CD流程:自动化测试和部署流程,确保代码质量。
蓝绿部署:减少部署风险,实现无缝切换。
3. 模型监控
性能监控:跟踪准确率、召回率等关键指标。
异常检测:实时监控模型行为,及时发现并修复问题。
4. 反馈循环
用户反馈:收集用户使用模型时的反馈。
迭代改进:根据反馈调整模型,持续提升性能。
模型维护
1. 版本控制
模型版本:为每个发布版本打标签,便于追踪和管理。
配置文件:存储模型配置信息,方便复现实验。
2. 文档编写
模型卡片:记录模型的用途、性能、限制等。
操作手册:提供详细的使用和维护指南。
3. 灾难恢复
备份策略:定期备份模型和数据。
恢复计划:制定应急响应流程以应对系统故障。
相关问答
Q1: 如何确保模型在生产环境中的稳定性?
A1: 确保模型稳定性的方法包括严格的测试流程(单元测试、集成测试)、持续监控模型性能指标、设置性能阈值警报、以及快速回滚机制,采用蓝绿部署和灰度发布可以降低模型更新时的风险。
Q2: 模型管理中如何处理数据漂移问题?
A2: 数据漂移是指模型训练数据与实际生产数据分布不一致的情况,处理方法包括定期重新训练模型以吸收新数据、实施模型监控系统以检测数据分布的变化、以及使用概念漂移检测算法来自动识别和适应数据变化。
【版权声明】:本站所有内容均来自网络,若无意侵犯到您的权利,请及时与我们联系将尽快删除相关内容!


发表回复