
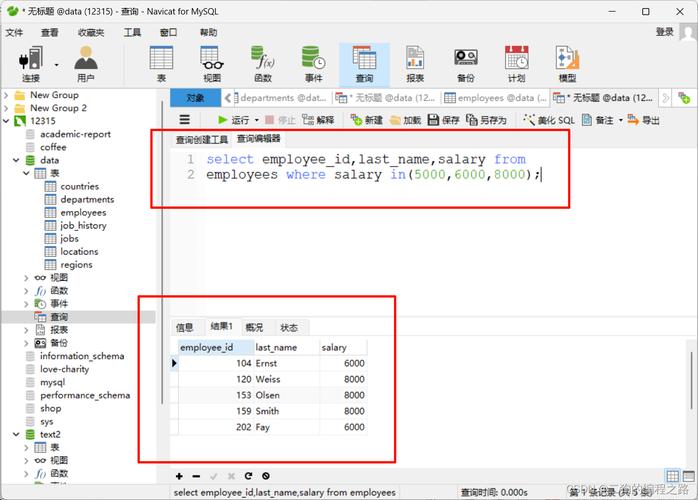
DISTINCT关键字来去除查询结果中的重复数据。如果你有一个名为students的表,并且想要查询所有不重复的城市名称,你可以使用以下查询:,,“sql,SELECT DISTINCT city FROM students;,“在数据库设计中,避免数据重复是一个重要的问题,这不仅涉及到数据的一致性和可维护性,还关系到查询效率和存储空间的优化,本文将探讨如何在MySQL数据库中去除重复数据,并给出一些实际的去重策略。

1. 理解数据冗余与重复
数据冗余指的是同一数据在不同地方重复出现,而数据重复则是指数据库中存在多条相同的记录,这些重复可能源于数据导入时的不准确、用户操作错误或者系统设计的不合理。
2. 使用主键(Primary Key)
确保每张表都有一个主键是避免数据重复的最基本方法,主键是唯一标识表中每一行数据的字段或字段组合,通过设置主键,可以保证表中不会出现完全相同的两行数据。
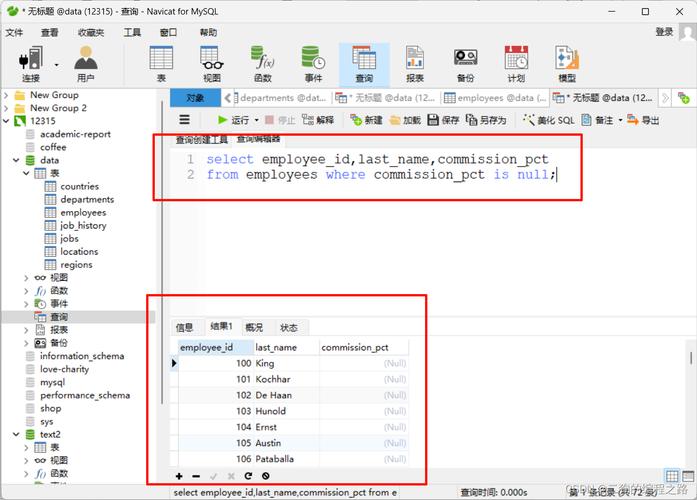
如果我们有一个users表:
| id | name | |
| 1 | John | john@example.com |
| 2 | Jane | jane@example.com |
在这个表中,id字段被设置为主键,这样就能保证每个用户都有唯一的ID。
3. 使用唯一约束(Unique Constraints)
对于非主键字段,可以使用唯一约束来避免该字段的值出现重复,这通常用于如电子邮件地址、用户名等需要保持唯一性的字段。
在上述users表中,我们可以为email字段添加唯一约束:
ALTER TABLE users ADD UNIQUE (email);
4. 使用联合唯一约束(Composite Unique Constraints)
有时单一字段不足以保证记录的唯一性,此时可以使用多个字段的组合来创建联合唯一约束。
一个订单表orders可能需要订单号和用户ID的组合唯一:
| order_id | user_id | product |
| 001 | 1 | A |
| 002 | 1 | B |
| 003 | 2 | A |
可以这样创建联合唯一约束:
ALTER TABLE orders ADD UNIQUE (order_id, user_id);
5. 使用删除重复语句
如果已经存在重复的数据,可以使用SQL语句来删除,假设我们有一个没有主键的orders表,并且有多条重复的订单记录,我们可以这样删除重复:
DELETE o1 FROM orders o1 INNER JOIN orders o2 WHERE o1.id > o2.id AND o1.order_id = o2.order_id;
这个语句会比较order_id相同的记录,并删除其中ID较大的记录,从而保留一条唯一的记录。
6. 使用临时表和插入选择
在某些复杂的情况下,可以先创建一个临时表,然后将去重后的数据插入到这个临时表中,最后再将临时表的数据导入到原表中。
CREATE TEMPORARY TABLE temp_orders AS SELECT * FROM orders GROUP BY order_id; TRUNCATE orders; INSERT INTO orders SELECT * FROM temp_orders;
相关问题与解答
Q1: 如果表中已经有大量的重复数据,我应该如何处理?
A1: 如果表中已经有大量的重复数据,首先需要确定哪些字段或字段组合能够唯一标识记录,可以使用GROUP BY语句结合聚合函数来选出唯一的记录,或者使用窗口函数来确定哪些是重复的记录,并据此进行删除操作,在操作之前,建议先备份数据以防万一。
Q2: 如何防止未来数据导入时产生重复?
A2: 为了防止未来数据导入时产生重复,可以在导入前对数据进行清洗,确保没有重复的记录,可以在数据库层面设置主键、唯一约束或触发器来自动拒绝重复数据的插入,还可以编写应用程序逻辑,在插入数据前检查是否存在重复,并采取相应的处理措施。
【版权声明】:本站所有内容均来自网络,若无意侵犯到您的权利,请及时与我们联系将尽快删除相关内容!


发表回复